import mlflow.sklearn from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression
# 加载数据集 iris = load_iris() X, y = iris.data, iris.target
def __init__(self, _expand__to_dot=EXPAND__TO_DOT, **params): self._params = {} for pname, pvalue in iteritems(params): if '__' in pname and _expand__to_dot: pname = pname.replace('__', '.') self._setattr(pname, pvalue)
]]>
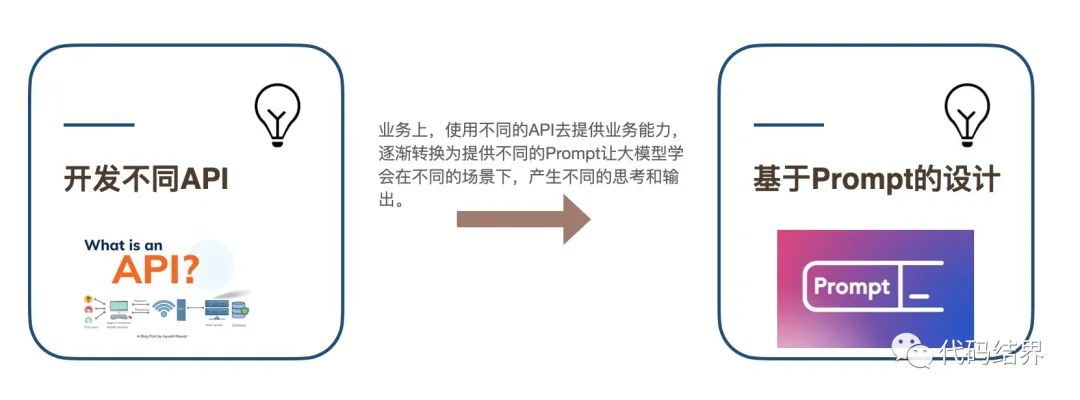
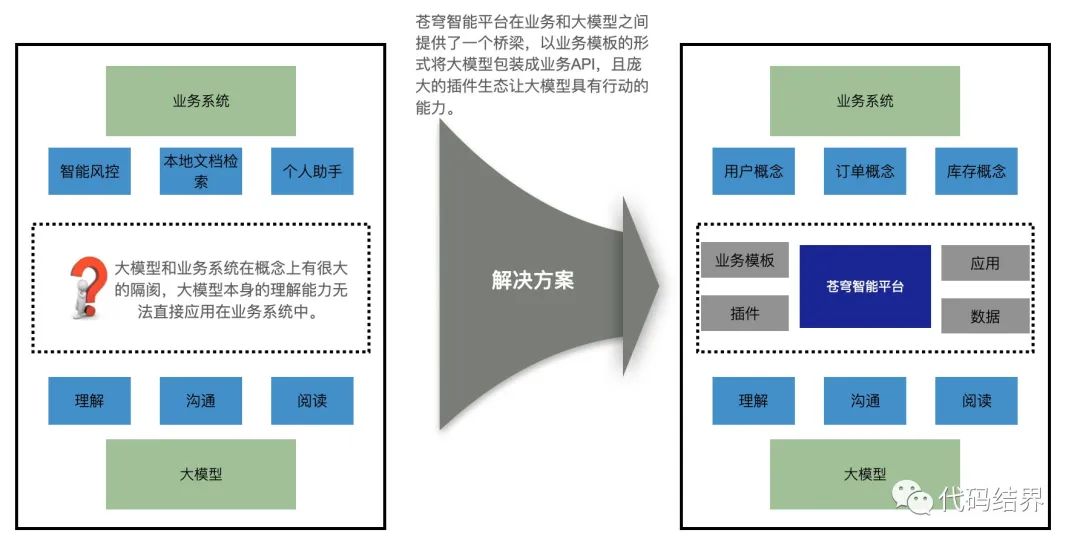
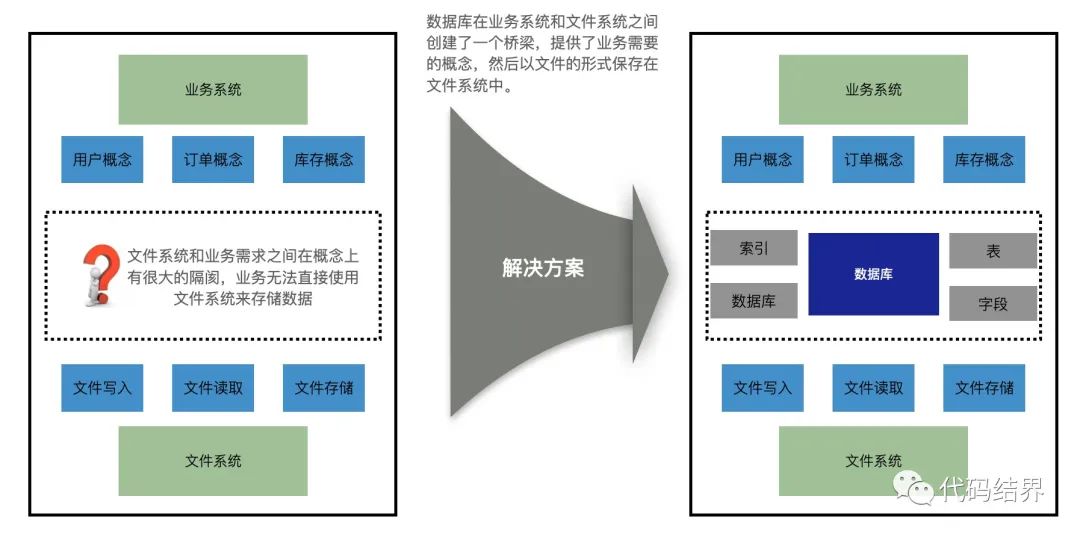
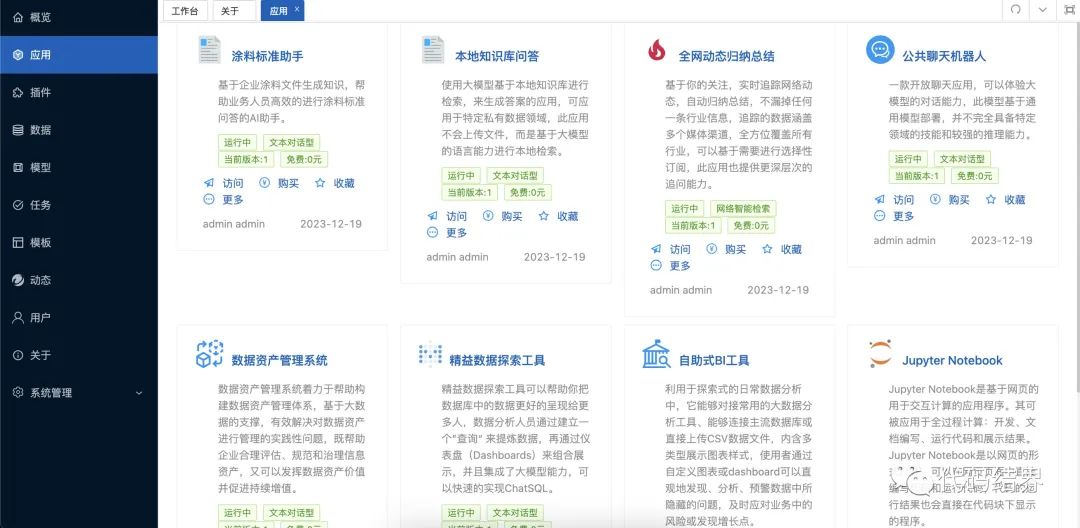
为什么那么多企业都要考虑All in AI
mlserver1.4.0开始对dataframe的序列化逻辑调整http://www.baifachuan.com/posts/7804e1a3.html2024-08-05T14:10:22.000Z2024-08-05T14:13:00.050Z最近对于本地私有化模型,我是通过seldon这一套进行封装,也就是最终是通过mlserver启动模型服务,然后外部调用mlserver的接口去做模型的推理。
TypeError: ufunc 'isnan' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
The NaN (Not a Number) value is used in Numpy and other scientific libraries to describe an invalid or missing value (e.g. a division by zero). In some scenarios, it may be desirable to let your models receive and / or output NaN values (e.g. these can be useful sometimes with GBTs, like XGBoost models). This is why MLServer supports encoding NaN values on your request / response payloads under some conditions.
In order to send / receive NaN values, you must ensure that:
- You are using the `REST` interface. - The input / output entry containing NaN values uses either the `FP16`, `FP32` or `FP64` datatypes. - You are either using the [Pandas codec](#pandas-dataframe) or the [Numpy codec](#numpy-array).
Assuming those conditions are satisfied, any `null` value within your tensor payload will be converted to NaN.
For example, if you take the following Numpy array:
import numpy as np import pandas as pd from mlserver.codecs import PandasCodec from mlserver.codecs.numpy import to_datatype from mlserver.codecs.pandas import _process_bytes from mlserver.codecs.utils import inject_batch_dimension from mlserver.types import InferenceRequest, Parameters, RequestInput, ResponseOutput, Datatype
def convert_nan(val): try: if np.isnan(val): return None except Exception: return val return val
]]>
TypeError ufunc isnan not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule safe
Docker container中的nvidia-smi无法看到其他地方启动的程序http://www.baifachuan.com/posts/4f6920d7.html2024-06-16T14:12:58.000Z2024-06-16T14:13:45.960Z当在docker container里面运行GPU程序的时候,通过 nvidia-smi 只能看到当前 container里面启动的程序,而无法看到所有运行在GPU上的程序,这个原因是因为nvidia-smi 这个命令通过扫描持有驱动的PID来查找对应的程序。
File "/usr/local/lib/python3.10/threading.py", line 973, in _bootstrap self._bootstrap_inner() File "/usr/local/lib/python3.10/threading.py", line 1016, in _bootstrap_inner self.run() File "/root/.cache/pypoetry/virtualenvs/knowledge-base-9TtSrW0h-py3.10/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 797, in run item = self.queue.get() File "/usr/local/lib/python3.10/queue.py", line 171, in get self.not_empty.wait() File "/usr/local/lib/python3.10/threading.py", line 320, in wait waiter.acquire()
大约一年前,大家热聊的先是LLM,LLM的全称是Large language models,也就是大语言模型,那么它必然有两个特点,一个是自然语言,第二个是大。 随后然后它带来了一个效果,就是能“生成”可以生成东西,可以像人一样发言,不过输出仅限于文本,看起来,能够自我输出和自我思考,于是基于这个理念,产生了AIGC这个概念应运而生。 紧接着,围绕它诞生了非常多看起来更加“多模态的东西”,比如文生图,图生文,但是背后实质上性是多个模型的配合完成这项工作。
<property> <description>Enable a set of periodic monitors (specified in yarn.resourcemanager.scheduler.monitor.policies) that affect the scheduler.</description> <name>yarn.resourcemanager.scheduler.monitor.enable</name> <value>false</value> </property>
]]>
Class not instance of CapacityScheduler
解决SuperSet加载样例数据出现网络不稳定的问题http://www.baifachuan.com/posts/9eb07da5.html2023-11-21T01:26:23.000Z2023-11-21T01:27:23.610ZSuperset的安装挺简单的,基本就几个命令:
# Create an admin user in your metadata database (use `admin` as username to be able to load the examples) export FLASK_APP=superset superset fab create-admin
# Load some data to play with superset load_examples
# Create default roles and permissions superset init
# Build javascript assets cd superset-frontend npm ci npm run build cd ..
# To start a development web server on port 8088, use -p to bind to another port superset run -p 8088 --with-threads --reload --debugger
]]>
<p>Superset的安装挺简单的,基本就几个命令:</p>
<figure class="highlight plain"><table><tr><td class="code"><pre><span class="line"># Create an admin user i
Livy中对session的超时处理逻辑http://www.baifachuan.com/posts/55f6c433.html2023-10-12T08:52:02.000Z2023-10-12T08:53:52.693Z最近有反馈这样一个问题:通过note book给livy提交代码片段,无论代码有没有执行完毕,超过1小时后,作业都会被强制kill掉。 这里就需要了解到livy对session的超时管理机制,在livy里面,对于每一次来自客户的的请求,比如发送一个代码片段过来执行,整个过程称为一个session过程。 也就是说livy里面管理的session代表的就是和某一个客户端的链接,和yarn里面的app并不完全一对一的关联,也不和spark context完全一对一的关联,虽然大部分情况下都是一对一 比如极端情况,完全可以在自己的代码里面再造一个作业或者spark context出来。 回到livy的session的管理上来说,session有这样的状态:
def apply(s: String): SessionState = s match { case "not_started" => NotStarted case "starting" => Starting case "recovering" => Recovering case "idle" => Idle case "running" => Running case "busy" => Busy case "shutting_down" => ShuttingDown case "error" => Error() case "dead" => Dead() case "killed" => Killed() case "success" => Success() case _ => throw new IllegalArgumentException(s"Illegal session state: $s") }
// How long to check livy session leakage val YARN_APP_LEAKAGE_CHECK_TIMEOUT = Entry("livy.server.yarn.app-leakage.check-timeout", "600s") // how often to check livy session leakage val YARN_APP_LEAKAGE_CHECK_INTERVAL = Entry("livy.server.yarn.app-leakage.check-interval", "60s")
// Whether session timeout should be checked, by default it will be checked, which means inactive // session will be stopped after "livy.server.session.timeout" val SESSION_TIMEOUT_CHECK = Entry("livy.server.session.timeout-check", true)
// Whether session timeout check should skip busy sessions, if set to true, then busy sessions // that have jobs running will never timeout. val SESSION_TIMEOUT_CHECK_SKIP_BUSY = Entry("livy.server.session.timeout-check.skip-busy", false)
// How long will an inactive session be gc-ed. val SESSION_TIMEOUT = Entry("livy.server.session.timeout", "1h")
// How long a finished session state will be kept in memory val SESSION_STATE_RETAIN_TIME = Entry("livy.server.session.state-retain.sec", "600s")
// Max creating session in livyServer val SESSION_MAX_CREATION = Entry("livy.server.session.max-creation", 100)
/** * Opens a file, with the specified name, for overwriting or appending. * @param name name of file to be opened * @param append whether the file is to be opened in append mode */ private native void open0(String name, boolean append) throws FileNotFoundException;
drop table if exists testdb.testtbl; create table testdb.testtbl select * from testdb.store_sales;
会出现问题:
Error in query: Can not create the managed table('`testdb`.`testtbl`'). The associated location('s3a://bucket/testdb/testtbl') already exists.
SparkSQL这边也能看到如下日志:
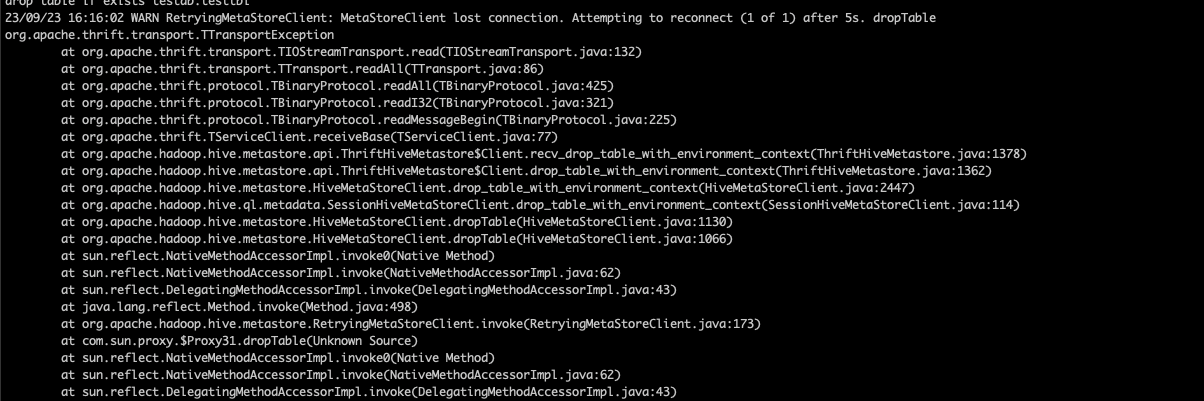
drop table if exists testdb.testtbl 23/09/23 16:16:02 WARN RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 5s. dropTable org.apache.thrift.transport.TTransportException at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132) at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:425) at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:321) at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:225) at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_drop_table_with_environment_context(ThriftHiveMetastore.java:1378) at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.drop_table_with_environment_context(ThriftHiveMetastore.java:1362) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.drop_table_with_environment_context(HiveMetaStoreClient.java:2447) at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.drop_table_with_environment_context(SessionHiveMetaStoreClient.java:114) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.dropTable(HiveMetaStoreClient.java:1130) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.dropTable(HiveMetaStoreClient.java:1066) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:173) at com.sun.proxy.$Proxy31.dropTable(Unknown Source) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2372) at com.sun.proxy.$Proxy31.dropTable(Unknown Source) at org.apache.hadoop.hive.ql.metadata.Hive.dropTable(Hive.java:1201)
我写了一个简单的demo就能复现这个开源的问题,进入SparkSQL执行如下SQL:
drop table if exists testdb.testtbl; create table testdb.testtbl select * from testdb.store_sales;
private boolean drop_table_core(final RawStore ms, final String catName, final String dbname, final String name, final boolean deleteData, final EnvironmentContext envContext, final String indexName) throws NoSuchObjectException, MetaException, IOException, InvalidObjectException, InvalidInputException { // 省略其他代码 if (!ms.dropTable(catName, dbname, name)) { String tableName = getCatalogQualifiedTableName(catName, dbname, name); throw new MetaException(indexName == null ? "Unable to drop table " + tableName: "Unable to drop index table " + tableName + " for index " + indexName); } else { if (!transactionalListeners.isEmpty()) { transactionalListenerResponses = MetaStoreListenerNotifier.notifyEvent(transactionalListeners, EventType.DROP_TABLE, new DropTableEvent(tbl, true, deleteData, this), envContext); } success = ms.commitTransaction(); } } finally { if (!success) { ms.rollbackTransaction(); } else if (deleteData && !isExternal) { // Data needs deletion. Check if trash may be skipped. // Delete the data in the partitions which have other locations deletePartitionData(partPaths, ifPurge, db); // Delete the data in the table deleteTableData(tblPath, ifPurge, db); // ok even if the data is not deleted }
if (!listeners.isEmpty()) { MetaStoreListenerNotifier.notifyEvent(listeners, EventType.DROP_TABLE, new DropTableEvent(tbl, success, deleteData, this), envContext, transactionalListenerResponses, ms); } } return success; }
drop table if exists testdb.testtbl; create table testdb.testtbl select * from testdb.store_sales;
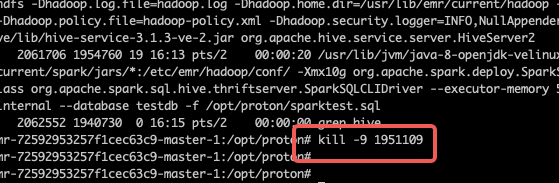
为例,当执行drop table的时候,通过kill -9 杀死hms,会看到spark这边出现:
23/09/23 16:16:02 WARN RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 5s. dropTable org.apache.thrift.transport.TTransportException
的错误,此时hms中表已经不存在了:
desc testdb.testtbl; Error in query: Table or view not found: testdb.testtbl; line 1 pos 5; 'DescribeRelation false, [col_name#15, data_type#16, comment#17] +- 'UnresolvedTableOrView [testdb, testtbl], DESCRIBE TABLE, true
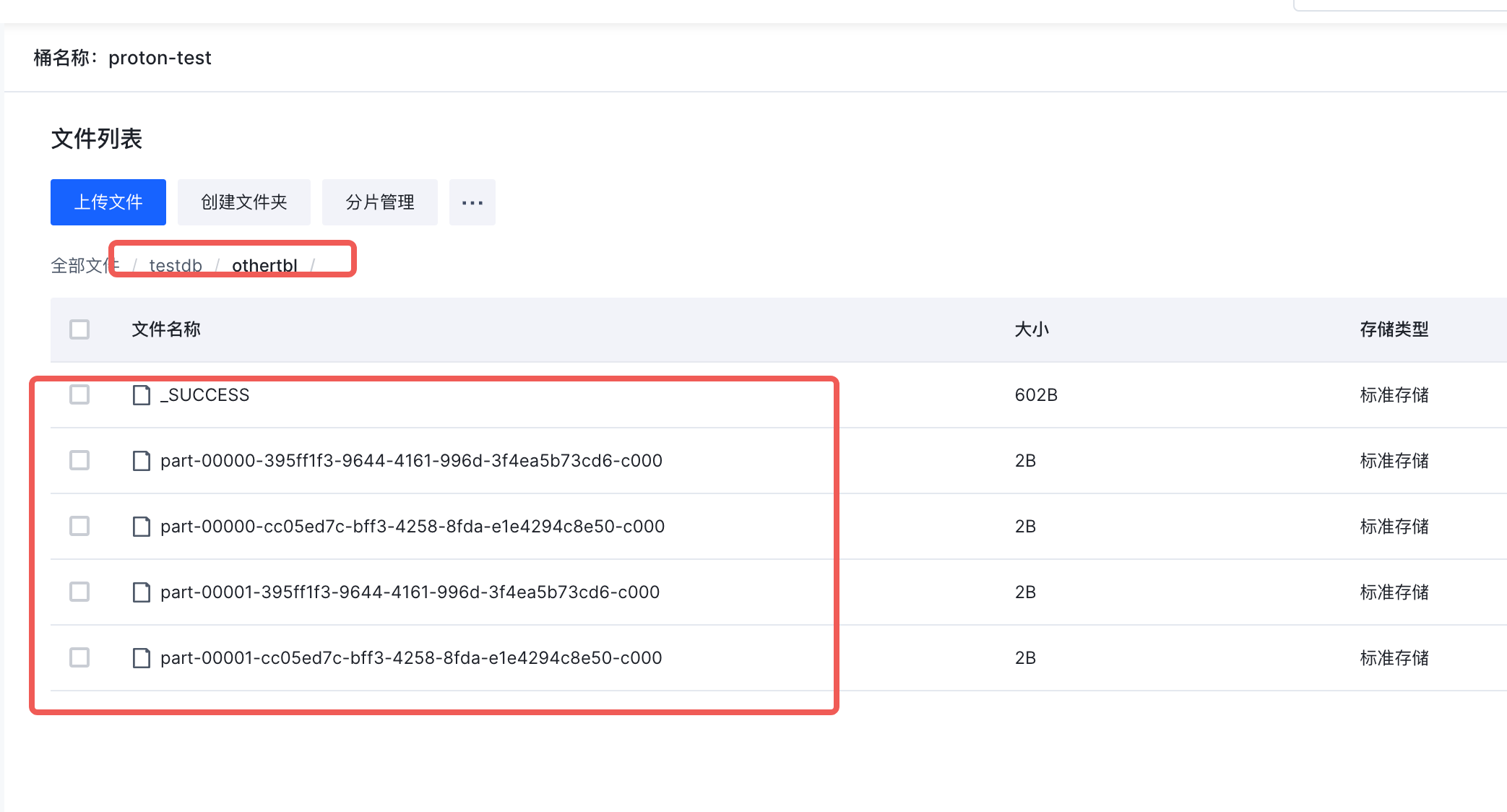
但表背后的底层物理数据依旧存在,此时去执行:
create table testdb.testtbl select * from testdb.store_sales;
的时候就会出现:
Error in query: Can not create the managed table('`testdb`.`testtbl`'). The associated location('s3a://bucket/testdb/testtbl') already exists.
因为在SparkSQL通过create select的方式去写hive表的时候,会额外做校验:
private def validateNewLocationOfRename( oldName: TableIdentifier, newName: TableIdentifier): Unit = { val oldTable = getTableMetadata(oldName) if (oldTable.tableType == CatalogTableType.MANAGED) { val databaseLocation = externalCatalog.getDatabase(oldName.database.getOrElse(currentDb)).locationUri val newTableLocation = new Path(new Path(databaseLocation), formatTableName(newName.table)) val fs = newTableLocation.getFileSystem(hadoopConf) if (fs.exists(newTableLocation)) { throw QueryCompilationErrors.cannotOperateManagedTableWithExistingLocationError( "rename", oldName, newTableLocation) } } }
def cannotOperateManagedTableWithExistingLocationError( methodName: String, tableIdentifier: TableIdentifier, tableLocation: Path): Throwable = { new AnalysisException(s"Can not $methodName the managed table('$tableIdentifier')" + s". The associated location('${tableLocation.toString}') already exists.") }
]]>
Error in query Can not create the managed table xx. The associated location xx already exists
如何把HDFS文件系统mount到本地http://www.baifachuan.com/posts/6eacaab6.html2023-09-22T02:55:23.000Z2023-09-22T02:55:57.909Zhdfs支持把fs mount到本地,这种需求的使用场景基本集中在AI上,hadoop从2开始,就支持通过fuse的方式把fs mount上去。