为什么企业都会去优化Spark Shuffle Service
shuffle动作指的是需要把数据从某个地方搬到另一个地方,一般在大数据框架下大家优化的思路也是尽可能减少shuffle的动作,例如通过算子变化操作把多次shuffle归为一次。
用transform动作去替换action的动作取消shuffle的动作的产生,这些手段都是使用者基于某些框架去做的使用层面的优化。
拿Spark来说,除了使用Spark的时候会有很多优化去解决使用层面的最佳实践外,很多企业会直接动手修改Spark内核自身,对shuffle机制进行翻天覆地的改造,那么为啥企业最后都会去动shuffle呢?
当Spark程序在运行的时候,会有很多组件配合工作,例如Yarn做资源管理,NameNode负责数据元信息的处理,DataNode负责数据的传输,也就是当一个Spark跑在Yarn集群上的时候。
Spark会启动自己的Driver,这个Driver所在位置也就是Yarn启动Spark的时候定义的ApplicationMaster的节点,Spark自己的Executor会运行在Hadoop的DataNode上。
假设一个Spark程序由10个节点共同运行的,需要做一个shuffle动作,例如group by,那么各个节点之间比如涉及到数据的传输和汇总,最终在一个节点上统计出最终的group by。
默认情况下数据传输是有Executor这个jvm程序负责处理,也就是Executor进程除了运行task,还要负责写shuffle数据,给其他Executor提供shuffle数据。
如果这个时候当Executor进程任务过重,导致GC而不能为其他Executor提供shuffle数据时,会影响任务运行,导致整个集群不稳定,基本就类似管理动作和数据传输动作放在一起了。
显然这么明显的问题,Spark不会留着不管,所以Spark提供了External shuffle Service,External shuffle Service是长期存在于NodeManager进程中的一个辅助服务。
通过该服务来抓取shuffle数据,减少了Executor的压力,在Executor GC的时候也不会影响其他Executor的任务运行。
既然有了External shuffle Service,各个大厂为什么还觉得不满意,需要继续优化,像阿里的Spark Remote Shuffle Service,几乎每家大厂都搞了自己的shuffle service 呢?
因为即便是External shuffle Service,他的数据依旧放在Executor的节点上,也就是被data node的节点负责管理,本质上在传输的时候会占据data node 的io,会影响其他独立的yarn的程序,毕竟os层面来说io是多任务共享。
其次当企业数据量太大,用户太多,会造成并发极速下降,随着任务数量上来,临时存储容量诉求会大涨,对于这种固定集群,非纯云原生的架构来说弹性力度跟不上,另外分布式情况下随着引入的因素越多,稳定越差,最终会导致整个集群出现不健康的状态。
再有就是很多Spark程序是跑在K8S上面,因此对这类Spark Shuffle需要依赖大量当前节点的本地存储的场景,天然就不友好,也和k8s的容错机制不兼容,造成出现问题后,任务的整体恢复成本非常高。
归纳下来就是:
- Spark Shuffle Fetch过程存在大量的网络小包,现有的External Shuffle Service设计并没有非常细致的处理这些RPC请求,大规模场景下会有很多connection reset发生,导致FetchFailed,从而导致stage重算。
- Spark Shuffle Fetch过程存在大量的随机读,大规模高负载集群条件下,磁盘IO负载高、CPU满载时常发生,极容易发生FetchFailed,从而导致stage重算。
- 重算过程会放大集群的繁忙程度,抢占机器资源,导致恶性循环严重,SLA完不成,需要运维人员手动将作业跑在空闲的Label集群。
- 计算和Shuffle过程架构不能拆开,不能把Shuffle限定在指定的集群内,不能利用部分SSD机器。
- M*N次的shuffle过程:对于10K mapper,5K reducer级别的作业,基本跑不完。
- NodeManager和Spark Shuffle Service是同一进程,Shuffle过程太重,经常导致NodeManager重启,从而影响Yarn调度稳定性。
Spark社区在2019年其实也在开始思考这种场景的问题,进行了一些讨论:https://issues.apache.org/jira/browse/SPARK-25299?spm=a2c6h.12873639.0.0.3c4b194d4ExHWP
该Issue主要希望解决的问题是在云原生环境下,Spark需要将Shuffle数据写出到远程的服务中。但是我们经过调研后发现Spark 3.0(之前的master分支)只支持了部分的接口,而没有对应的实现。该接口主要希望在现有的Shuffle代码框架下,将数据写到远程服务中。如果基于这种方式实现,比如直接将Shuffle以流的方式写入到HDFS或者Alluxio等高速内存系统,会有相当大的性能开销。
所以各个大厂都在考虑从自身的角度,如何完美的把计算和数据传输真正切分开,这就诞生了在Spark基础上还需要再次优化shuffle的需求,那么一般大家怎么优化呢?
其实思路差不多,既然shuffle是用来做数据传输,传输的内容是Executor计算出放在data node上的临时文件,那么就在Executor写入临时文件的时候把它放到另外的地方去,读取的时候让其他节点从其他地方去读就好了。
这个其他地方就非常重要了,他需要解决高io,高并发,高性能,从而不影响整个程序进行,另外因为是其他地方,所以自然也就解决了K8S场景下,对磁盘和数据存储的诉求,可以极大的利用K8S的优势,进行无缝的融合了,完美解决Spark on Kubernetes方案中对于本地磁盘的依赖。
像阿里的Remote Shuffle Service,就是一个完整的缓存服务器:
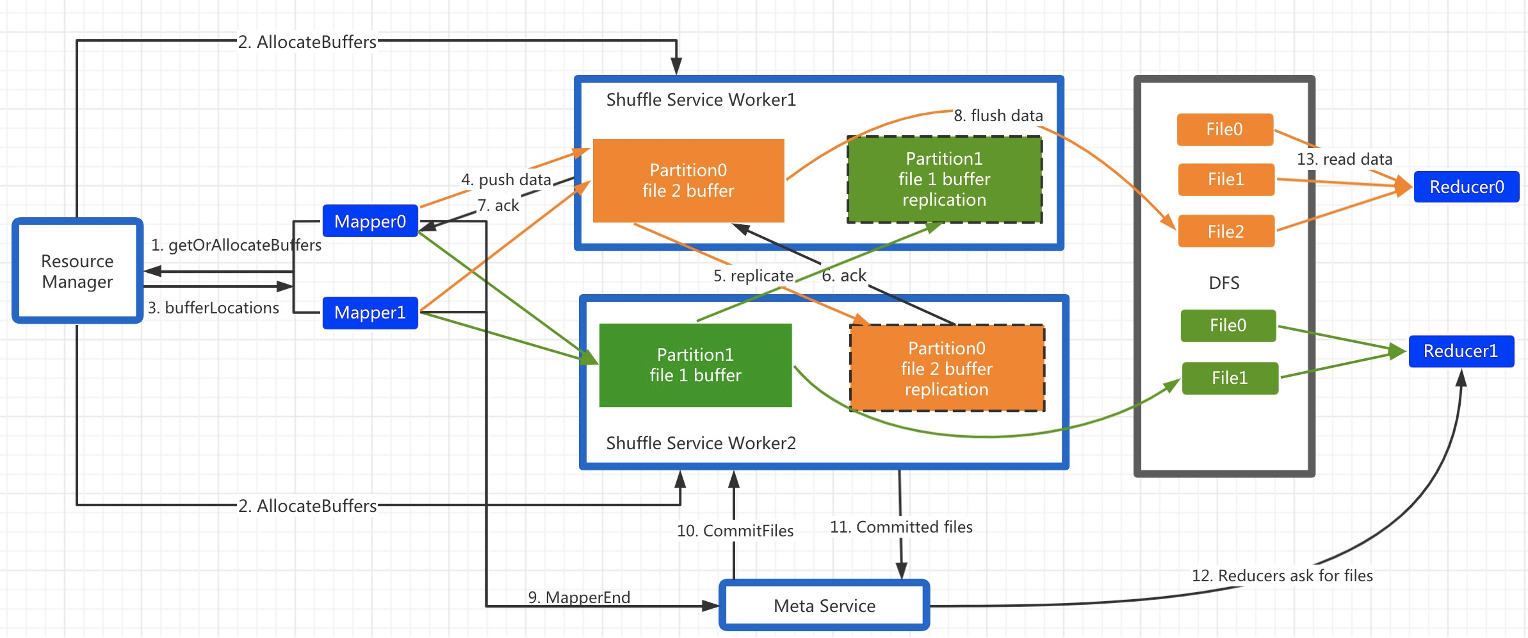
Spark RSS架构包含三个角色: Master, Worker, Client。Master和Worker构成服务端,Client以不侵入的方式集成到Spark ShuffleManager里(RssShuffleManager实现了ShuffleManager接口)。
实现流程是:
- RSS采用Push Style的shuffle模式,每个Mapper持有一个按Partition分界的缓存区,Shuffle数据首先写入缓存区,每当某个Partition的缓存满了即触发PushData。
- Driver先和Master发生StageStart的请求,Master接受到该RPC后,会分配对应的Worker Partition并返回给Driver,Shuffle Client得到这些元信息后,进行后续的推送数据。
- Client开始向主副本推送数据。主副本Worker收到请求后,把数据缓存到本地内存,同时把该请求以Pipeline的方式转发给从副本,从而实现了2副本机制。
- 为了不阻塞PushData的请求,Worker收到PushData请求后会以纯异步的方式交由专有的线程池异步处理。根据该Data所属的Partition拷贝到事先分配的buffer里,若buffer满了则触发flush。RSS支持多种存储后端,包括DFS和Local。若后端是DFS,则主从副本只有一方会flush,依靠DFS的双副本保证容错;若后端是Local,则主从双方都会flush。
- 在所有的Mapper都结束后,Driver会触发StageEnd请求。Master接收到该RPC后,会向所有Worker发送CommitFiles请求,Worker收到后把属于该Stage buffer里的数据flush到存储层,close文件,并释放buffer。Master收到所有响应后,记录每个partition对应的文件列表。若CommitFiles请求失败,则Master标记此Stage为DataLost。
- 在Reduce阶段,reduce task首先向Master请求该Partition对应的文件列表,若返回码是DataLost,则触发Stage重算或直接abort作业。若返回正常,则直接读取文件数据。
总体来讲,RSS的设计要点总结为3个层面:
- 采用PushStyle的方式做shuffle,避免了本地存储,从而适应了计算存储分离架构。
- 按照reduce做聚合,避免了小文件随机读写和小数据量网络请求。
- 做了2副本,提高了系统稳定性。
像其他大厂大家都差不多,优化思路基本都是围绕这个方向,大部分企业都有自己的存储或者缓存系统,把shuffle对接到这类系统上也是合情合理,于是自然就催生了对spark的具体改造。`
扫码手机观看或分享: