Spark并行度的理解与配置
在调整Spark并行度的时候有2个参数: spark.default.parallelism 和 spark.sql.shuffle.partitions。
首先两者最直观的区别:
- spark.default.parallelism只有在处理RDD时有效。
- spark.sql.shuffle.partitions则是只对SparkSQL有效。
官方文档描述如下:
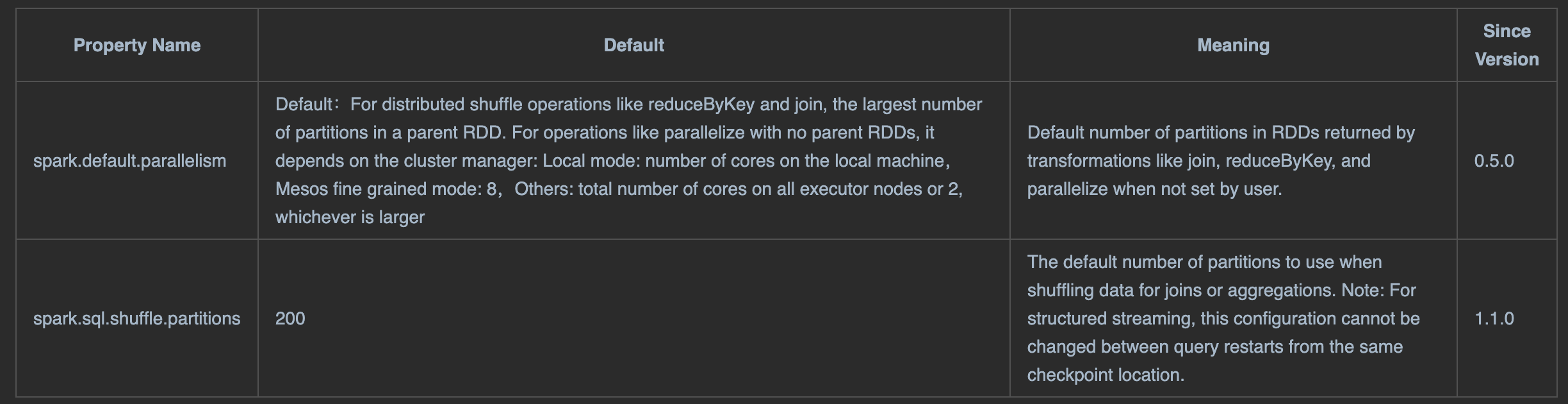
spark.sql.shuffle.partitions: 设置的是 RDD1做shuffle处理后生成的结果RDD2的分区数.
默认值: 200
spark.default.parallelism: 设置的是 RDD1做shuffle处理/并行处理(窄依赖算子)后生成的结果RDD2的分区数
默认值:
- 对于分布式的shuffle算子, 默认值使用了结果RDD2所依赖的所有父RDD中分区数最大的, 作为自己的分区数.
- 对于并行处理算子(窄依赖的), 有父依赖的, 结果RDD分区数=父RDD分区数, 没有父依赖的看集群配置:
- Local mode:给定的core个数
- Mesos fine grained mode: 8
- Others: max(RDD分区数为总core数, 2)
并行度其实就是指的是spark作业中, 各个stage的taskset中的task的数量, 代表了spark作业中各个阶段的并行度, 而taskset中的task数量 = task任务的父RDD中分区数。
官网建议: 设置为当前spark job的总core数量的2~3倍. 理由如下:
背景: spark作业是 1 core 1 task
假设我们给当前Spark job 设置总Core数为 100, 那么依据1 core 1 task, 当前spark集群中最多并行运行100task任务, 那么通过设置上述两个参数为100, 使得我们结果RDD的分区数为100, 一个分区 1task 1core, 完美!
但是实际生产中会有这样的情况, 100个task中有些task的处理速度快, 有些处理慢, 假设有20个task很快就处理完毕了, 此时就会出现 我们集群中有20个core处理闲置状态, 不符合spark官网所说的最大化压榨集群能力.
而如果我们设置上述参数值为199, 此时的现象: 虽然集群能并行处理199个task, 奈何总core只有100, 所以会出现有99个task处于等待处理的情况. 处理较快的那20task闲置下来的20个core就可以接着运行99个中的20个task, 这样就最大化spark集群的计算能力
扫码手机观看或分享: