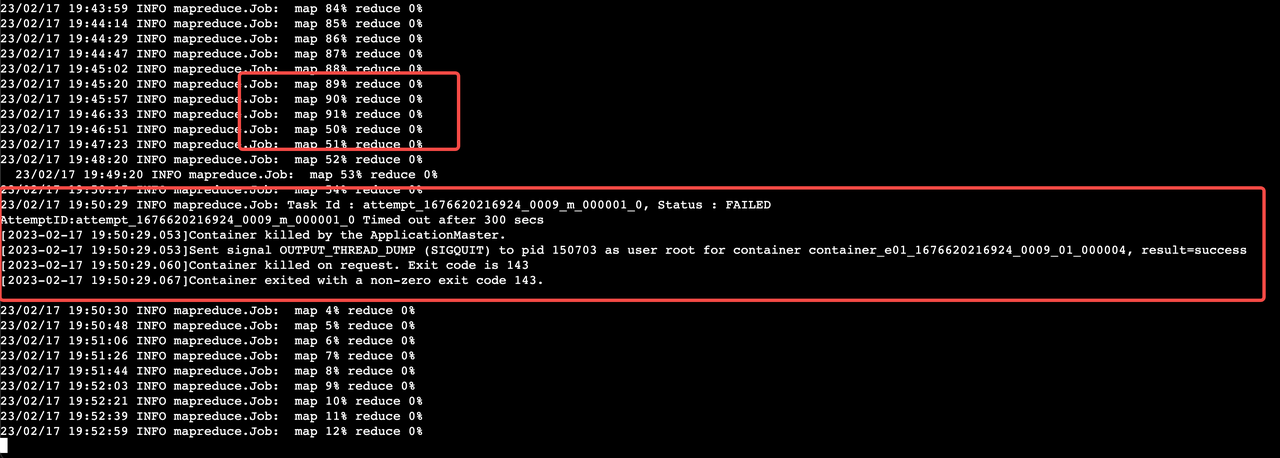
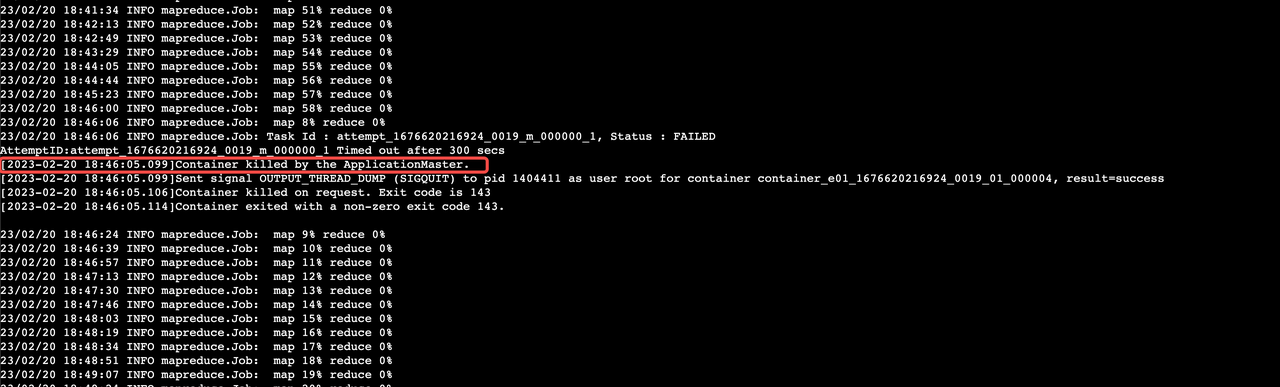
23/03/03 13:46:31 INFO mapreduce.Job: Task Id : attempt_1677815879112_0001_m_000001_0, Status : FAILED AttemptID:attempt_1677815879112_0001_m_000001_0 task timeout set: 300s, taskTimedOut: true; task stuck timeout set: 600s, taskStuck: false [2023-03-03 13:46:30.483]Sent signal OUTPUT_THREAD_DUMP (SIGQUIT) to pid 2583362 as user root for container container_e12_1677815879112_0001_01_000003, result=success [2023-03-03 13:46:30.487]Container killed by the ApplicationMaster. [2023-03-03 13:46:30.501]Container killed on request. Exit code is 143 [2023-03-03 13:46:30.503]Container exited with a non-zero exit code 143.
23/03/03 13:46:31 INFO mapreduce.Job: Task Id : attempt_1677815879112_0001_m_000000_0, Status : FAILED AttemptID:attempt_1677815879112_0001_m_000000_0 task timeout set: 300s, taskTimedOut: true; task stuck timeout set: 600s, taskStuck: false [2023-03-03 13:46:30.483]Sent signal OUTPUT_THREAD_DUMP (SIGQUIT) to pid 2732317 as user root for container container_e12_1677815879112_0001_01_000002, result=success [2023-03-03 13:46:30.487]Container killed by the ApplicationMaster. [2023-03-03 13:46:30.497]Container killed on request. Exit code is 143 [2023-03-03 13:46:30.498]Container exited with a non-zero exit code 143.