大数据组件新秀Kuyybi和Linkis
Spark SQL以及Flink SQL在SQL 引擎的视角来看做了很多优化,但是两者都缺少一个SQL服务器,可以用在生产环境的服务区,虽然Spark SQL有一个Spark Thrift Server,但是由于其设计原因。
在并发,跨队列提交,权限等方面都有诸多问题,所以实际应用并不广泛。
我曾参与开发了一个Spark SQL服务器,用来解决这类问题,具体的内容可以看:https://baifachuan.com/posts/bad642ff.html
实际上从业界来说,也有不少新秀组件,也在做着类似的事,首先是kyuubi:https://github.com/apache/incubator-kyuubi
kyuubi关注的很早,也和相关的人员聊过,kyuubi除了提供SQL服务器的能力外解决了另一个问题,就是SQL网关的问题。
通过SQL网关去屏蔽多组件多集群多版本带来的上层运维问题,同时又保留了原始的组件接口,但是kyuubi有一个问题就是背后关联的引擎是在kyuubi启动的时候以启动参数进行绑定的。
这会大大限制gateway的发展,比较好的方式是采用session级别的灵活控制,通过sql hint或者alter的方式去调整背后的引擎。
kyuubi团队也有此方面的打算, 可以以 ANSI-like 的方式扩展一部分 SQL 语法:https://github.com/apache/shardingsphere/releases
而提到网关服务的时候,还有另一个比较优秀的开源组件incubator-linkis:https://github.com/apache/incubator-linkis
它的两张图很直接明白的说明了一切:
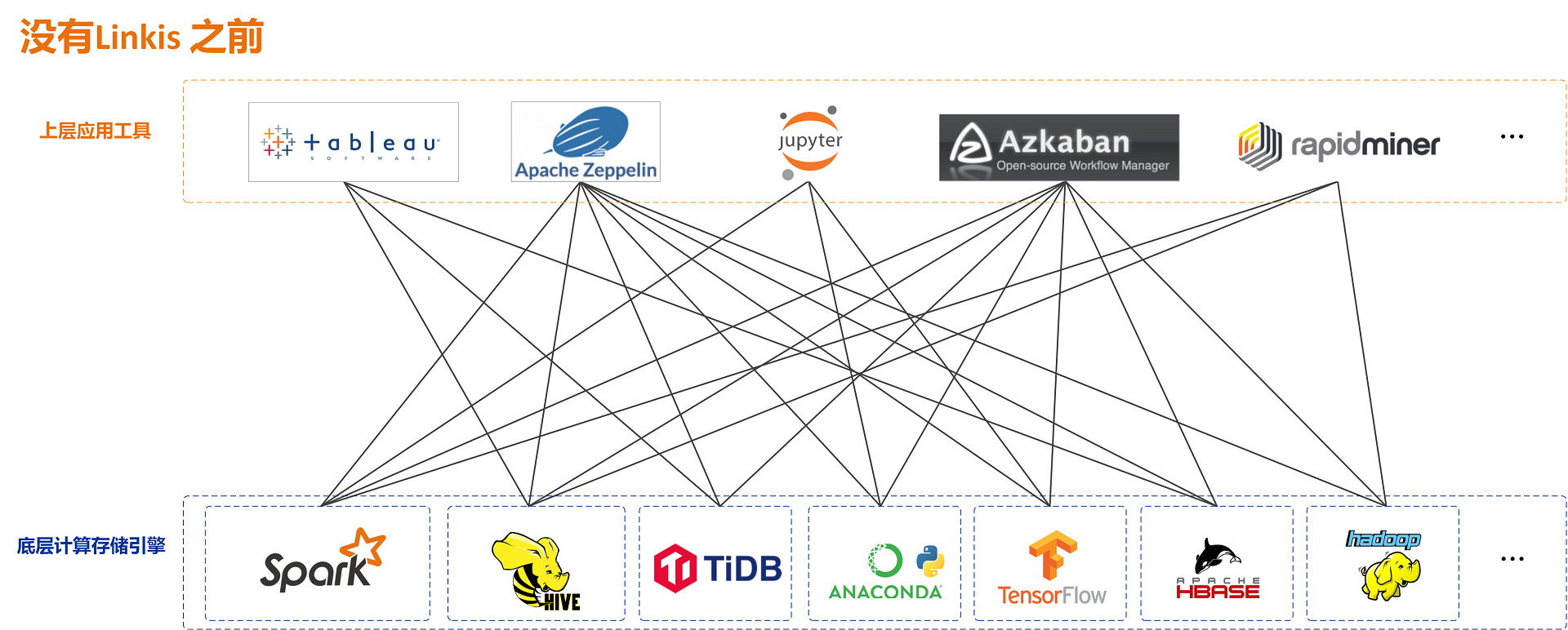
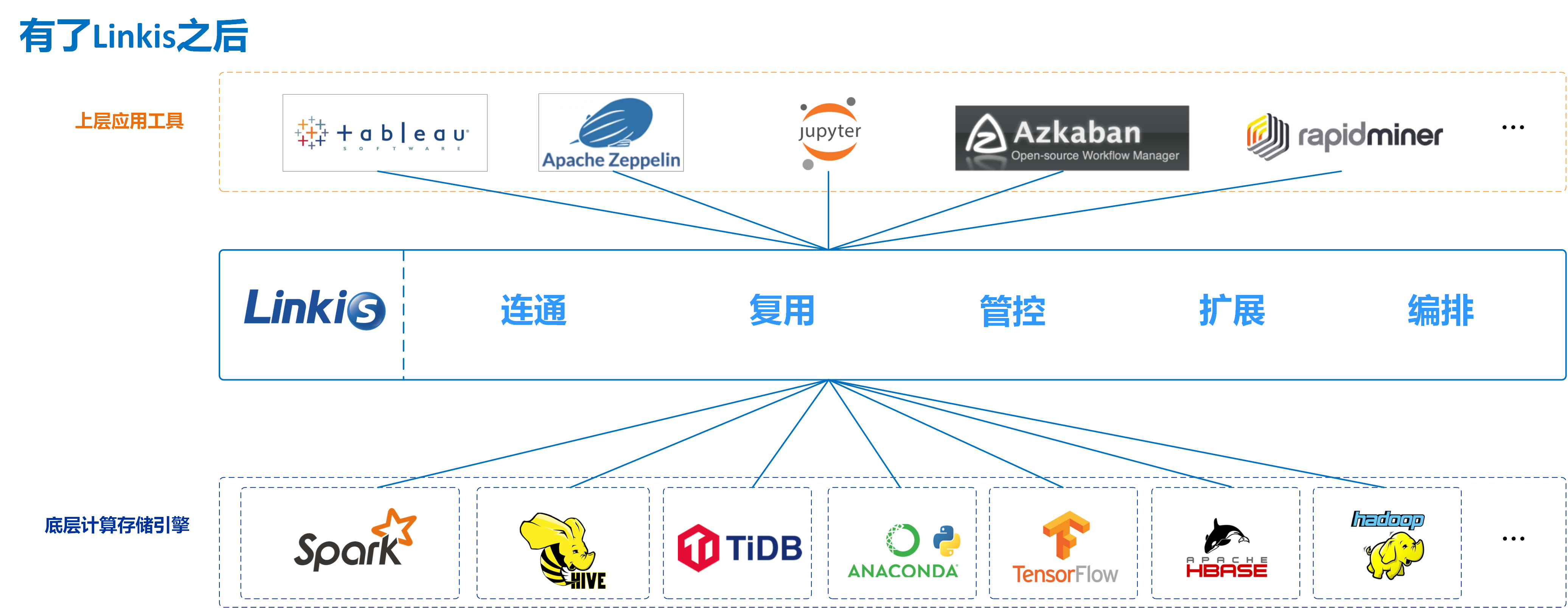
Linkis 在上层应用程序和底层引擎之间构建了一层计算中间件。通过使用Linkis 提供的REST/WebSocket/JDBC 等标准接口,上层应用可以方便地连接访问MySQL/Spark/Hive/Presto/Flink 等底层引擎,同时实现变量、脚本、函数和资源文件等用户资源的跨上层应用互通。
作为计算中间件,Linkis 提供了强大的连通、复用、编排、扩展和治理管控能力。通过计算中间件将应用层和引擎层解耦,简化了复杂的网络调用关系,降低了整体复杂度,同时节约了整体开发和维护成本。
无论是kyuubi还是linkis,都是很不错的组件,可以值得参考。
扫码手机观看或分享: