drop table if exists testdb.testtbl; create table testdb.testtbl select * from testdb.store_sales;
会出现问题:
Error in query: Can not create the managed table('`testdb`.`testtbl`'). The associated location('s3a://bucket/testdb/testtbl') already exists.
SparkSQL这边也能看到如下日志:
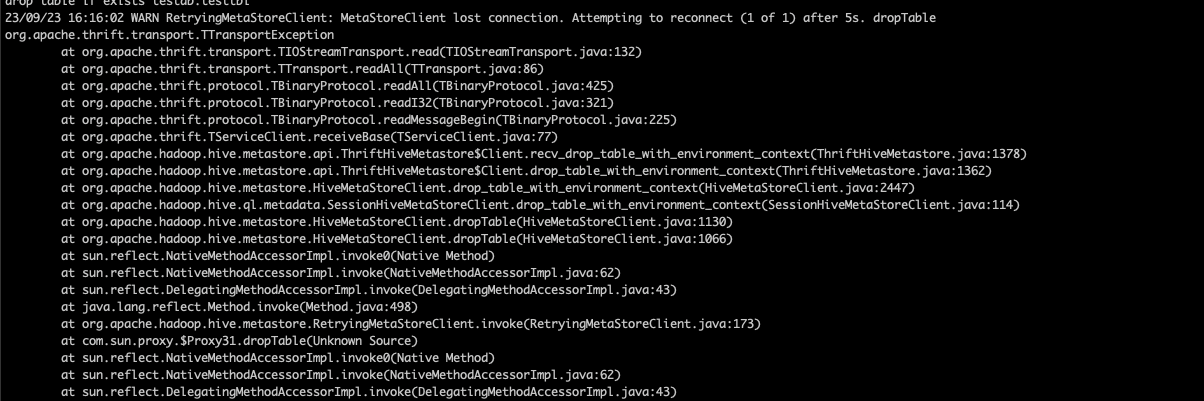
drop table if exists testdb.testtbl 23/09/23 16:16:02 WARN RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 5s. dropTable org.apache.thrift.transport.TTransportException at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132) at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:425) at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:321) at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:225) at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_drop_table_with_environment_context(ThriftHiveMetastore.java:1378) at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.drop_table_with_environment_context(ThriftHiveMetastore.java:1362) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.drop_table_with_environment_context(HiveMetaStoreClient.java:2447) at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.drop_table_with_environment_context(SessionHiveMetaStoreClient.java:114) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.dropTable(HiveMetaStoreClient.java:1130) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.dropTable(HiveMetaStoreClient.java:1066) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:173) at com.sun.proxy.$Proxy31.dropTable(Unknown Source) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2372) at com.sun.proxy.$Proxy31.dropTable(Unknown Source) at org.apache.hadoop.hive.ql.metadata.Hive.dropTable(Hive.java:1201)
我写了一个简单的demo就能复现这个开源的问题,进入SparkSQL执行如下SQL:
drop table if exists testdb.testtbl; create table testdb.testtbl select * from testdb.store_sales;
private boolean drop_table_core(final RawStore ms, final String catName, final String dbname, final String name, final boolean deleteData, final EnvironmentContext envContext, final String indexName) throws NoSuchObjectException, MetaException, IOException, InvalidObjectException, InvalidInputException { // 省略其他代码 if (!ms.dropTable(catName, dbname, name)) { String tableName = getCatalogQualifiedTableName(catName, dbname, name); throw new MetaException(indexName == null ? "Unable to drop table " + tableName: "Unable to drop index table " + tableName + " for index " + indexName); } else { if (!transactionalListeners.isEmpty()) { transactionalListenerResponses = MetaStoreListenerNotifier.notifyEvent(transactionalListeners, EventType.DROP_TABLE, new DropTableEvent(tbl, true, deleteData, this), envContext); } success = ms.commitTransaction(); } } finally { if (!success) { ms.rollbackTransaction(); } else if (deleteData && !isExternal) { // Data needs deletion. Check if trash may be skipped. // Delete the data in the partitions which have other locations deletePartitionData(partPaths, ifPurge, db); // Delete the data in the table deleteTableData(tblPath, ifPurge, db); // ok even if the data is not deleted }
if (!listeners.isEmpty()) { MetaStoreListenerNotifier.notifyEvent(listeners, EventType.DROP_TABLE, new DropTableEvent(tbl, success, deleteData, this), envContext, transactionalListenerResponses, ms); } } return success; }
drop table if exists testdb.testtbl; create table testdb.testtbl select * from testdb.store_sales;
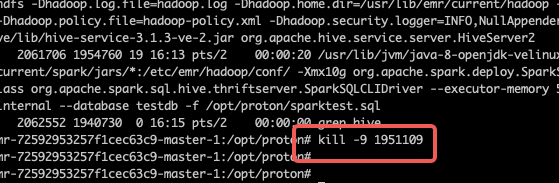
为例,当执行drop table的时候,通过kill -9 杀死hms,会看到spark这边出现:
23/09/23 16:16:02 WARN RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 5s. dropTable org.apache.thrift.transport.TTransportException
的错误,此时hms中表已经不存在了:
desc testdb.testtbl; Error in query: Table or view not found: testdb.testtbl; line 1 pos 5; 'DescribeRelation false, [col_name#15, data_type#16, comment#17] +- 'UnresolvedTableOrView [testdb, testtbl], DESCRIBE TABLE, true
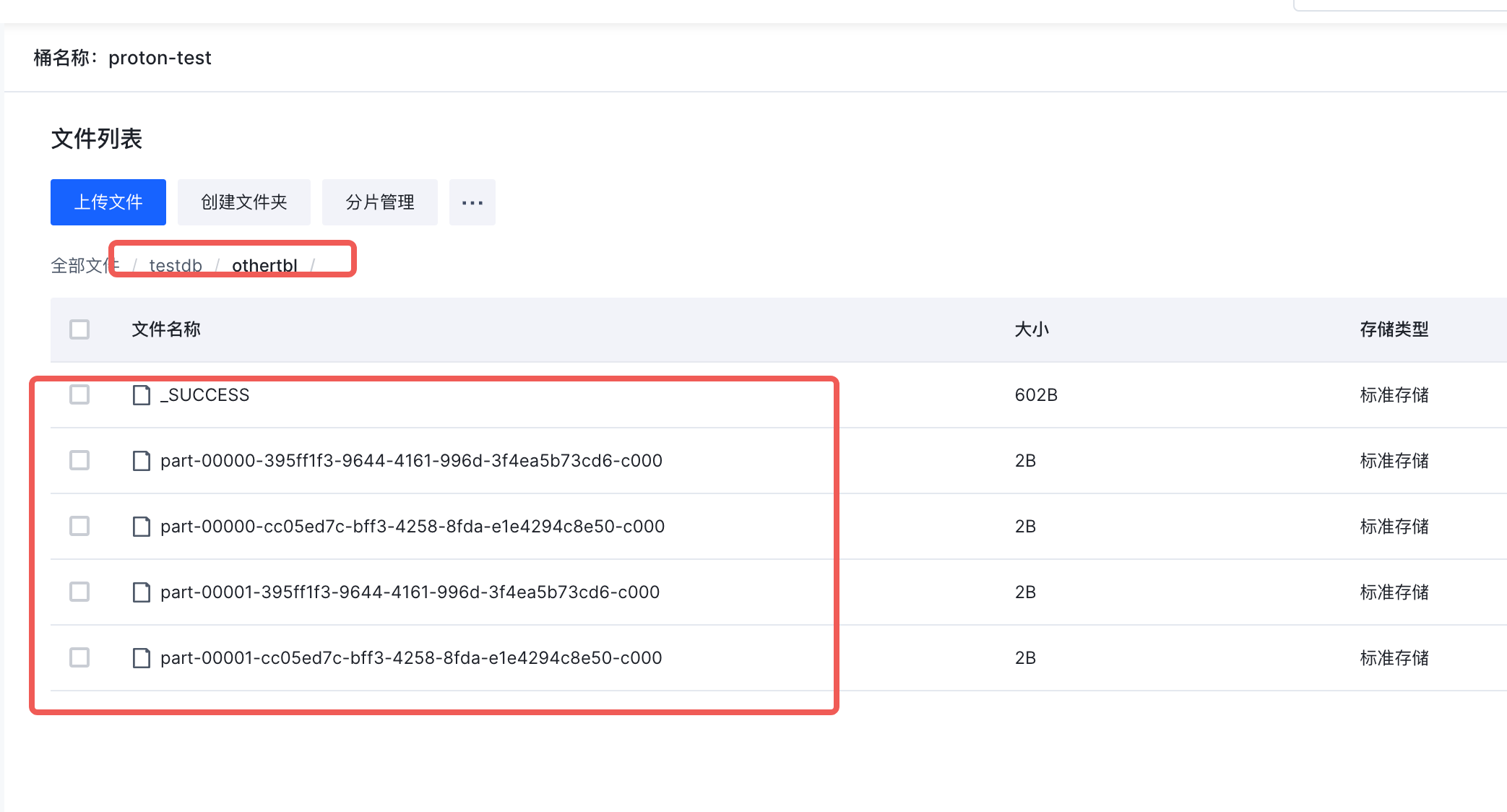
但表背后的底层物理数据依旧存在,此时去执行:
create table testdb.testtbl select * from testdb.store_sales;
的时候就会出现:
Error in query: Can not create the managed table('`testdb`.`testtbl`'). The associated location('s3a://bucket/testdb/testtbl') already exists.
因为在SparkSQL通过create select的方式去写hive表的时候,会额外做校验:
private def validateNewLocationOfRename( oldName: TableIdentifier, newName: TableIdentifier): Unit = { val oldTable = getTableMetadata(oldName) if (oldTable.tableType == CatalogTableType.MANAGED) { val databaseLocation = externalCatalog.getDatabase(oldName.database.getOrElse(currentDb)).locationUri val newTableLocation = new Path(new Path(databaseLocation), formatTableName(newName.table)) val fs = newTableLocation.getFileSystem(hadoopConf) if (fs.exists(newTableLocation)) { throw QueryCompilationErrors.cannotOperateManagedTableWithExistingLocationError( "rename", oldName, newTableLocation) } } }
def cannotOperateManagedTableWithExistingLocationError( methodName: String, tableIdentifier: TableIdentifier, tableLocation: Path): Throwable = { new AnalysisException(s"Can not $methodName the managed table('$tableIdentifier')" + s". The associated location('${tableLocation.toString}') already exists.") }