利用Bert模型实现中文情感分析
什么是Bert
BERT (Bidirectional Encoder Representations from Transformers)
2018年10月11日,Google AI Language 发布了论文
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
提出的 BERT 模型在 11 个 NLP 任务上的表现刷新了记录,包括问答 Question Answering (SQuAD v1.1),推理 Natural Language Inference (MNLI) 等:
GLUE :General Language Understanding Evaluation |
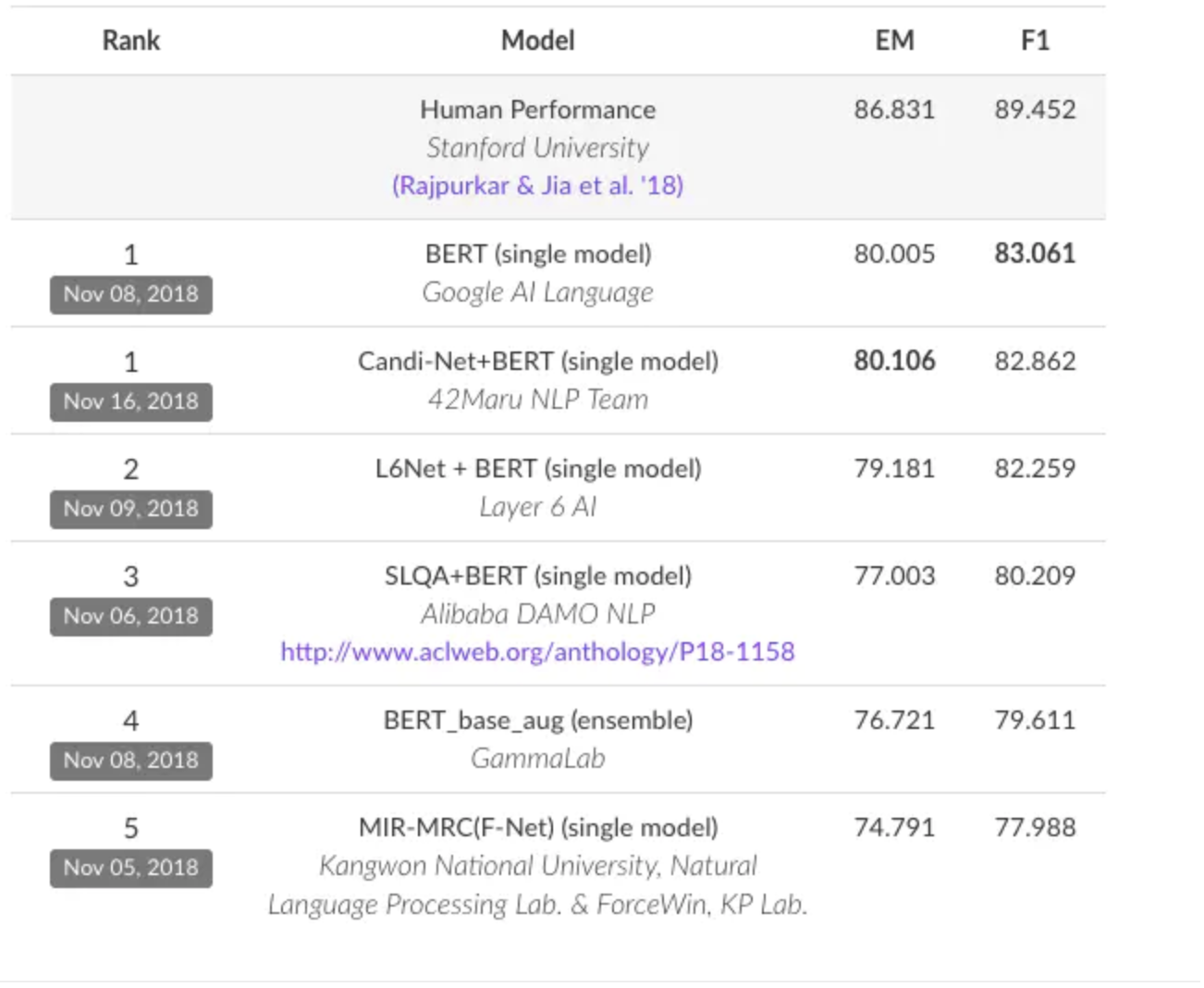
点击查看BERT 在 Stanford Question Answering Dataset (SQuAD) 上面的排行榜
大概我截图了一下,如下所示:
Bert能用来干什么?
BERT 可以用于问答系统,情感分析,垃圾邮件过滤,命名实体识别,文档聚类等任务中,作为这些任务的基础设施即语言模型,
BERT 的代码也已经开源:
https://github.com/google-research/bert
我们可以对其进行微调,将它应用于我们的目标任务中,BERT 的微调训练也是快而且简单的。
例如在 NER 问题上,BERT 语言模型已经经过 100 多种语言的预训练,这个是 top 100 语言的列表:
https://github.com/google-research/bert/blob/master/multilingual.md
只要在这 100 种语言中,如果有 NER 数据,就可以很快地训练 NER。
那么今天我们要做的是使用Bert做一个中文的情感分类的例子,总体来说因为有TF和Bert这种框架在,其实某种意义上留给我们定制化的东西并不多,更多的是理解它的使用方法,再进一步能够理解知道具体的内部原理会更好些。
Bert做情感分类
对于数据集来说我使用的是大约7000 多条酒店评论数据,5000 多条正向评论,2000多条负向评论,这些评论数据有两个字段:label, review,预览如下:

1表示正向评论,0表示负向评论,数据集可以在这里下载:
以上内容都在一个文件内,因为涉及到训练,基于Bert做二次训练,所以我们需要把文件先进行预处理,基本就是广播体操似的三份,简单的代码如下:
import pandas as pd |
有了训练需要的数据之后,我们需要使用Bert现有的模型,因为对于Bert来说可以很好的支持对模型进行二次修改开发,点击进入到Bert的rep页面:https://github.com/google-research/bert 然后点击如下的地方下载大约有360MB的预先训练好的模型:

解压后可以看到几个文件,一般这几个文件我们 只载入,不改动:
- bert_model.ckpt : 负责模型变量载入
- vocab.txt : 训练中文文本所采用的字典
- bert_config.json : BERT在训练时,配置的一些参数
接下来我们开始进行模型修改,做情感分类。
这是一个文本分类项目,使用BERT源码里的 run_classifier.py 文件即可训练,所以需要先把我上面那个链接的code rep的内容先拉下来,在训练之前,还需要根据实际的任务,对模型做以下简单的修改,在 run_classifier.py 中新建class,具体的内容如下:
class SentimentAnalysisProcessor(DataProcessor): |
在run_classifier.py的main中新增入口的调用方式:
processors = { |
其中的senti是新增的短名,也就是任务名称,在这里是什么,那么在训练脚本中的task_name就应该填什么。接下来开始训练模型,训练模型的时候需要做如下工作:
- 新建数据集目录data_set:把前面生成的train.tsv, dev.tsv, test.tsv放到data_set目录下
- 新建模型输出目录output
- 把预训练模型chinese_L-12_H-768_A-12上传到对应的目录下
训练脚本如下:
指定你使用哪个GPU |
运行脚本后可以看到如下的输出,也就是训练正式开始:
以上代码是基于tf1.x的api进行开发的,所以如果默认安装tf的话,会安装最新版本的到2.x在api层面不兼容,要么修改api将源码修改为2.0的,要么安装1.x的tf。
训练完成后,在output目录下可以看到很多文件:

model.ckpt 这些是模型文件,eval_results.txt:这个是验证集的评估文件,可以看到咱们未调参就有 0.907 的准确率。

test_results.tsv这个是测试集的评估文件,输出的是测试集每条评论,是正向评论还是负面评论的概率。

本文使用BERT模型的原始参数就获得了0.907的准确率,后续建议读者调试 run_classifier.py 中的以下超参数以获取更好的模型效果:
- max_seq_length:最大序列长度,超过这个长度的文本会被切割,不足这个长度会被填充,如果文本较长,可以从128调到256,甚至512
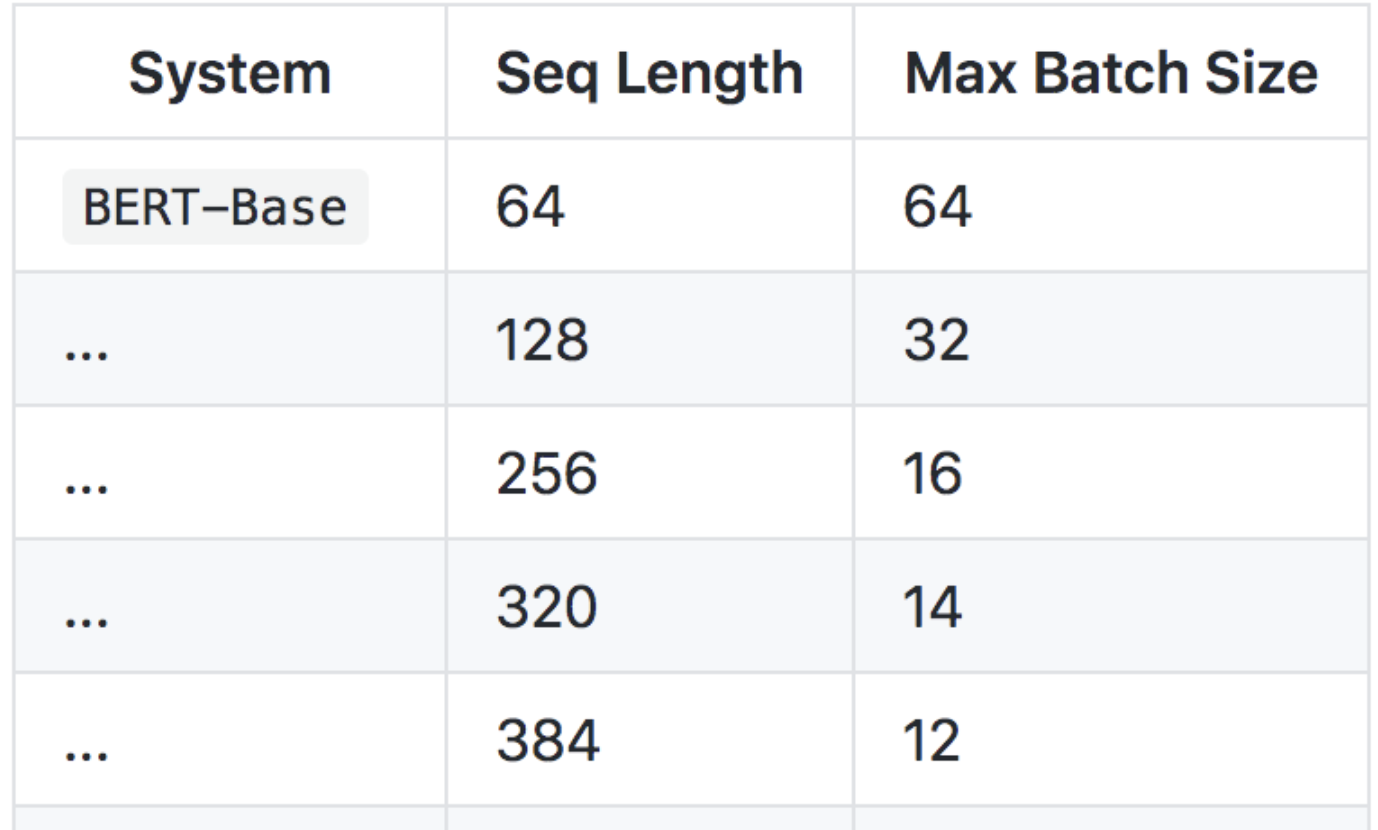
- train_batch_size:如果max_seq_length变大,这个参数就得变小,不然会出现显存资源不足的问题:具体对应关系可以参照:
- learning_rate:学习率, 可以试试3e-3,1e-3等等
- num_train_epochs: 全体训练集样本训练轮数,可以适当调大些,如:3 -> 5 -> 8,但是不要过大,防止模型过拟合
以上,就很简单的实现了一个基于Bert模型的中文情感识别分类问题,在实际使用中我们还需要添加很多额外的工程化处理,例如针对篇章,段落的处理,将篇章和段落进行拆句子,分别有了对应的概率后再汇总。
扫码手机观看或分享: