import requests
from bs4 import BeautifulSoup
text_file_name = "files/缠中说禅.txt"
md_file_name = "files/缠中说禅.md"
markdown_template = "files/markdown/template.md"
markdown_post_dir = "files/markdown/posts/"
def write_to_md_file(context):
with open(md_file_name, "a+") as f:
f.write(context)
f.flush()
def write_to_text(context):
with open(text_file_name, "a+") as f:
f.write(context)
f.flush()
def write_to_markdown_post(article_body_url, title_name, category, create_time, content_body):
content_body = '。\n'.join(content_body.split("。"))
title_name = title_name.replace("/", "-")
with open(markdown_template) as f:
lines = f.readlines()
context_template = ''.join(lines)
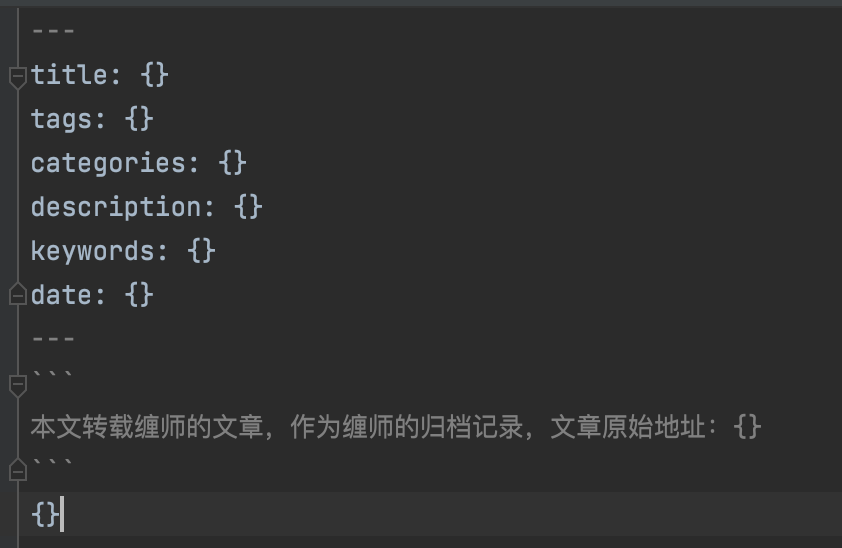
full_content_body = context_template.format(title_name,
category,
category,
title_name,
title_name,
create_time,
article_body_url,
content_body)
with open(markdown_post_dir + title_name + ".md", "w") as f:
f.write(full_content_body)
f.flush()
def download_article_body(article_body_url):
r = requests.get(article_body_url)
soup = BeautifulSoup(str(r.content, 'utf-8'))
title_name = soup.find(class_="articalTitle").find(class_="titName SG_txta").text.strip()
create_time = soup.find(class_="articalTitle").find(class_="time SG_txtc").text.strip()
category = "无分类"
if soup.find(class_="blog_class").find('a') is not None:
category = soup.find(class_="blog_class").find('a').text.strip()
content_body = soup.find(class_="articalContent").text.strip()
full_context = "\n{} - {} - {} \n{} \n".format(title_name, category, create_time, content_body)
write_to_text(full_context)
content_body_md = '。\n'.join(content_body.split("。"))
md_full_context = "\n## {} \n### {} \n### {} \n {}".format(title_name, category, create_time, content_body_md)
write_to_md_file(md_full_context)
write_to_markdown_post(article_body_url, title_name, category, create_time, content_body)
def worker(page_url):
print("Starting process:", page_url)
r = requests.get(page_url)
r.raise_for_status()
soup = BeautifulSoup(str(r.content, 'utf-8'))
for article_list in soup.find_all(class_="atc_title"):
article_body_url = article_list.find('a', href=True).attrs['href']
download_article_body(article_body_url)
if soup.find(class_="SG_pgprev") is None:
print("This is first page.")
if soup.find(class_="SG_pgnext") is not None:
next_url = soup.find(class_="SG_pgnext").find('a', href=True).attrs['href']
print("Fetch the next page:", next_url)
worker(next_url)
else:
print("The is the last page.")
print("End the worker:", page_url)
if __name__ == '__main__':
url = "http://blog.sina.com.cn/s/articlelist_1215172700_0_1.html"
worker(url)
print("All the worker is done.")
|