Hive on Spark 与 Spark SQL的区别
Hive on Spark是由Cloudera发起,将Hive的查询作为Spark的任务提交到Spark集群上进行计算。通过该项目,可以提高Hive查询的性能,同时为已经部署了Hive或者Spark的用户提供了更加灵活的选择,从而进一步提高Hive和Spark的普及率。Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。
而Spark SQL的前身是Shark,是给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,其对Hive有太多依赖(如采用Hive的语法解析器、查询优化器等),2014年Spark团队停止对Shark的开发,将所有资源放Spark SQL项目上。Spark SQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive。
在分析区别之前,先看一下SQL语句通用解析执行过程:
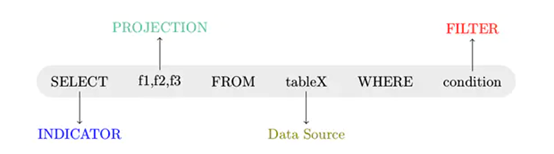
- 语法解析: 对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范,形成一个语法树;
- 操作绑定: 将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
- 策略优化:语法树中的每个节点是执行的rule,整棵树称之为执行策略。形成上述的执行策略树的执行策略可以进行优化(包括逻辑优化、生成物理计划和物理优化),所谓的优化就是对树中节点进行合并或是进行顺序上的调整,进而选择一个最优计划(Optimize),最终生成一棵任务树(Task Tree);
- 计划执行:依次执行(Execute)任务树中的各个Task,并将结果返回给用户。每个Task按照不同的实现,会把任务提交到不同的计算引擎上执行。
Hive on Spark总体的设计思路是,尽可能重用Hive逻辑层面的功能,从生成物理计划开始,提供一整套针对Spark的实现,比如Spark Compiler、Spark Task等,这样Hive的查询就可以作为Spark的任务来执行了。其设计的动机和主要原则有:
- Hive on Spark尽可能少改动Hive的代码,从而不影响Hive目前对MapReduce和Tez的支持,以及在功能和性能方面的影响;
- 对于选择Spark的用户,应使其能够自动的获取Hive现有的和未来新增的功能,如数据类型、UDF、逻辑优化等;
- 尽可能降低维护成本,保持对Spark依赖的松耦合,不做专门针对spark引擎,而对其它引擎有影响的改动。
Spark SQL是spark套件中一个模板,它将数据的计算任务通过SQL的形式转换成了RDD的计算,类似于Hive通过SQL的形式将数据的计算任务转换成了MapReduce。Spark SQL的特点有:
- 和Spark Core的无缝集成,可以在写整个RDD应用的时候,配置Spark SQL来完成逻辑实现;
- 统一的数据访问方式,Spark SQL提供标准化的SQL查询;
- Hive的继承,Spark SQL通过内嵌的hive或者连接外部已经部署好的hive案例,实现了对hive语法的继承和操作;
- 标准化的连接方式,Spark SQL可以通过启动thrift Server来支持JDBC、ODBC的访问,将自己作为一个BI Server使用。
Hive On Spark大体与Spark SQL结构类似,只是SQL引擎不同,但是计算引擎都是Spark。将Spark作为计算引擎,性能会比传统的MapReduce快很多。华为云DLI服务全面兼容Spark能力,DLI SQL在封装Spark SQL的同时,集成了carbon和carbondata的全部功能,同时兼容传统的DataSource和hive语法建表,支持跨源访问多个服务的数据,增强了易用性,降低了使用门槛,同时避免了数据搬迁,从而实现高效的数据处理和检索。
扫码手机观看或分享: