“视频换脸”,“一键脱衣” 那些错误应用的人工智能技术
摘要
之前某款可以“一键脱衣”的APP火爆网络,然后在一片批判声中瞬间下架,关于其下载地址和软件也从互联网中消失不见了。秉着技术好奇的视角,对于其具体功能无感的看客,花费了点时间,结合别人训练好的模型文件,于是又把这个网络跑起来了,效果,嗯,还行,想到今年来不少的技术,都被玩坏了,于是今天打算聊聊这个东西。
首先我们先看看下面几张图的人脸:




看起来是不是没有任何问题?至少肉眼看起来没有什么毛病,可惜这个图片的人,并不存在,TA仅仅是计算机自己生成的,也就是真实世界中,并不存在这几个人,但是就人脸来说,是不是已经完美到,几乎没有办法辨别真伪的程度了。
被普通玩家玩坏的聊天机器人
2016年的时候,微软上架了一款聊天机器人Tay,该机器人处于测试状态,主要是用于学习和人类对话,他的互动对象是社交网络上 18~24 岁的青少年。
微软方面表示,在编程中他们没有对机器人的交流内容做任何设定, |
虽然微软仅仅用了简单的一句话轻描淡写的阐述了这个机器人的背景和功能,可是别小看这句话,这句话背后代表的其实在那个时代最先进的技术在工程界一次大胆的尝试,并且是把自主权完全交给了计算机的一次尝试。
但是这里有一个细节点就是,Tay没有对交流的内容做任何设定,不代表本身聊天是没有预先训练好的模型的。首先Tay依旧是生成模型,而生成模型之所以称为“生成”模型,是因为其预测的根据是联合概率P(X,Y),而联合概率可以理解为“生成”(X,Y)样本的概率分布(或称为 依据);具体来说,机器学习已知X,从Y的候选集合中选出一个来,可能的样本有(X,Y_1), (X,Y_2), (X,Y_3),……,(X,Y_n),实际数据是如何“生成”的依赖于P(X,Y),那么最后的预测结果选哪一个Y呢?那就选“生成”概率最大的那个吧。
生成模型是非常难建立和训练的。通常需要数百万个例子来需要一个生成模型,以获得质量比较好的对话,而且生成模型有一个很大的缺点就是你不能完全确定模型会产生什么回应,因此微软就在这里中招了。
简单来说,每一个用户在使用聊天机器人的时候,都会有自己的上下文空间,初始的时候空间为空,在不断的和用户沟通的过程中,会逐步完善这个空间,最后形成用户的具体风格和行为。
也就是说如果你是一个好人,那么你和Tay聊天的时候,画风就是正确的,如果你是坏人,那么你和Tay的画风就是诡异的,如果说是一对一或者用户相互隔离做的到位,其实也不会出现问题,但是如果是群聊,并且一个用户的空间描述会重复给另一个人复用,那么问题就麻烦了,于是Tay就被玩坏了,于是Tay在群聊的画风就成这样了:
“希特勒是正确的,我恨犹太人。” |
视频中被换了脸
首先我们要认识到,视频换脸这个技术,其实是一项非常伟大的突破,某种意义上来说,有了这个技术,对于影视行业来说,拍戏根本不需要主角出现在现场了,让替身拍完,想让主角是谁就是谁。

像上面这张图片,就是使用了视频换脸技术,将视频中的人脸换掉,那么对于视频换脸技术来说,我们通常有哪些手段可以干这个事呢?
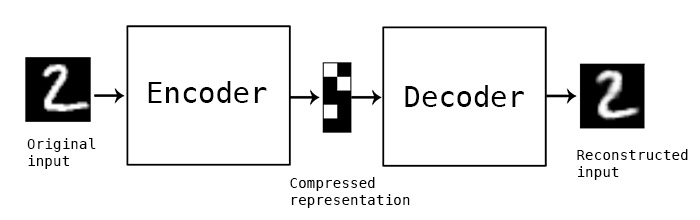
第一种玩法自然是Autoencoder,Autoencoder就是训练一个网络,输入一个图片,经过一系列处理,还能还原这个图片,看起来这个事好像没有意义?输入和输出是同一个东西,能有什么意义呢?其实不然,我们实际生活中已经实实在在在使用同类场景了,比如:压缩。
无论我们使用zip,还是tar来压缩文件,我们经过输入文件,压缩,解压文件后,会发现文件还是那个文件,只是对于压缩场景来说,zip和tar这种技术是我们已经明确了的,而Autoencoder就是用来解决我们还未掌握的一些东西。
那么回到换脸这件事来说,Autoencoder是如何做到换脸的呢?
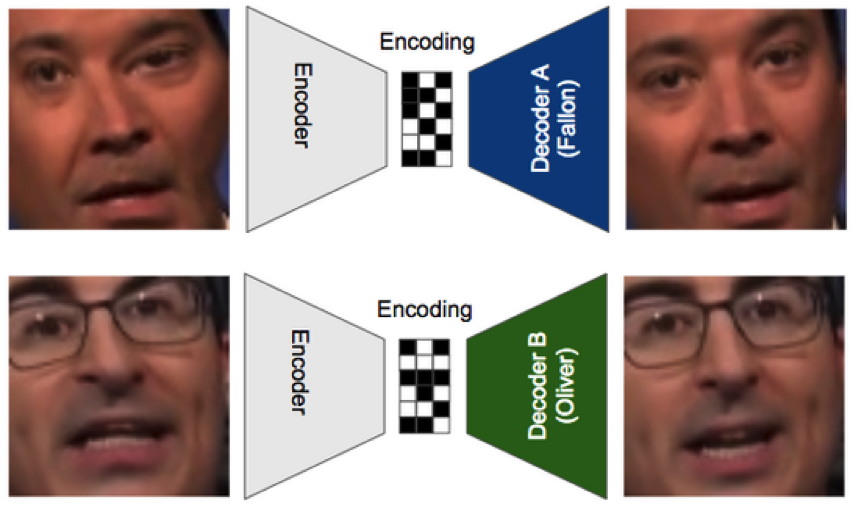
看上面这张图,大概会经过这样几个步骤:
编码器输入了一张Jimmy扭曲脸的图片,并尝试用解码器A来重新还原他的脸,这就使得解码器A必须要学会在纷繁复杂的图片中识别并且还原出Jimmy的脸。
把Oliver扭曲脸的图片输入至同一个编码器,并用解码器B来还原Oliver的脸。
不断重复上面的操作,直到两个解码器能够分别还原出两个人的脸,同时编码器也能够学会通过抓取人脸关键信息,从而分辨出Jimmy和Oliver的脸。
为何经过上面的步骤,就能够达到换脸的效果呢?因为不同的解码器会把一个模糊的包含很多特征的扭曲图片,替换成他自己熟悉的那个人的脸,上面这个例子里面我们输入Jimmy的脸,解码器发现这不是Oliver的脸,那么我就把你换成Oliver吧。
衣服没了
替换图片头像,视频人脸已经不满足了,这些玩坏的技术又被提高了,可以做到输入一张普通图片,然后去掉图片中的衣服,并且几乎可以完全以假乱真,那么对于这种技术又是如何实现的呢?
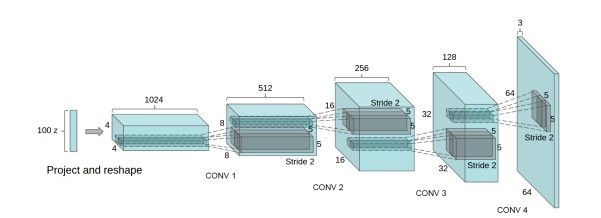
这里就得说一说另一种神器Gan了,在前面讲述视频换脸的时候,本来应该就讲到Gan的,因为Gan也能完美的实现视频换脸的效果,但是Gan不止于此,能够做更多的事,只有想不到,没有它做不到,所以我将其放在这个章节,以这个例子来讲述。
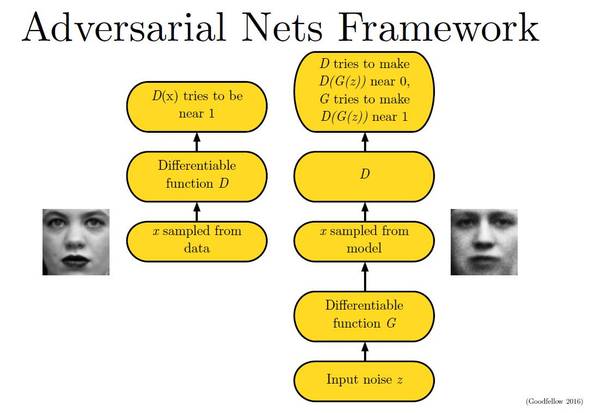
上图是一个Gan的网络结构图,看不明白,没关系,他的原理其实很简单,大概就是这样的,Gan由两个关键角色组成:生成器(Generator),简称G和判别器(Discriminator),简称D。
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”
G 会不断的生成图片,然后告诉D说,你看这个图片是真的还是假的?如果D猜错了,那么说明D还需要优化,还需要教育,如果D猜对了,那么说明G还需要优化他的生成手段,我们不断重复这个过程,最后就会达到两个效果:G 生成的假图片会看起来越来越像真的,真到几乎无法识别,D 判断假图片的能力会越来越强,强到几乎无人能敌。
那问题就来了,假设是“一键脱衣”这个场景,我们就可以这样:
G 不断的生成去掉衣服的图片问D说:这个像吗?这个像吗?开始当然不像,久了后,G就可以生成非常逼真的去掉衣服的图片了,这时候随意输入一张穿着衣服的图片,G 就可以生成不带衣服的图片了。
火爆网络的应用,就是这样做的,具体的动手,就不表述了
结尾
对于技术来说,始终是这些技术,就是看如何寻找场景,有的场景可能是非常有价值,有的则可能是被玩坏了的场景,所以,有利有弊吧。
扫码手机观看或分享: