演进式数据架构
摘要
演进式架构支持跨多个维度的引导性增量变更。 ——《演进式架构》 |
这是《演进式架构》这本书第一章第一节对 演进式架构 的作用做出的简洁定义,也就是说演进式架构便是持续架构,因为在架构这件事上没有最终状态,它会随着软件开发体系的不断变化而演进,我们只能通过时间和变化作为维度来定义和引导架构的走向。
《演进式架构》一书给软件系统架构如何进行演进给出了相对明确的方向,但是对于数据领域来说,不但目前所具备的基础设施相对落后,连数据系统构建相关的知识体系也异常匮乏,当我们尝试将业务型的软件系统架构中的最佳实践硬套到数据领域后,便会发现非常不兼容的状态。
例如微服务和数据服务天生冲突,微服务通过多个无状态的服务进行快速切换确保业务侧对于系统发生的宕机无感知,而数据服务天生具备的则是分布式多节点计算并且需要持续较长时间,要求任务具备高可用。DDD与数据建模也同样天生冲突,DDD基于聚合根将多个动作圈定在同一个上下文之下,结合云原生可以进行更好的弹性扩展,结合微服务的实现各个服务独享自有的存储,然而数据建模天生不是为某一个业务服务,而是为某一类或者多类业务服务,因此天生就不具备上下文的概念。
即便如此,我们依旧在不断探索,在这个领域有哪些更好的方向是值得我们去尝试的,有哪些更好的经验,值得我们借鉴的。本文便是借助于《演进式架构》这本书中关于演进式架构体系的描述,我们如何在数据这个领域,设计出演进式数据架构。
数据架构的类型
大部分场景之下,我们所看到的数据架构,更多是按照企业阶段或者业务性质来定义的,例如数据仓库,大数据平台,大数据仓库甚至智能平台。这样的架构定义之间的跨度非常大,甚至几乎不存在“演进”的可能性,几乎就是替换和重做,因此这种数据架构的定义相对太过于狭义,不太适用于我们去探讨数据架构如何演进,因为看起来这样的系统没有演进,直接步入到的是重做。
让我们重新审视和定义一下数据架构的类型,那么从大的方向来说我们可以将数据架构划分为一体化架构,分布式架构和领域分布式架构,仔细拆开来看是这样的形态:

即便是数据仓库,也是有不同的实现,最简单的便是嵌套在业务系统中,没有所谓的物理上的数据仓库的概念,业务系统在生产数据的同时也承担着数据仓库的职责,这种系统相对来说很容易的就能抽象演变成独立的数据仓库系统。
除了内嵌到业务系统之外,也有不少企业选择构建数仓的形式为在业务系统开启一个备库,然后基于备库进行BI+DB的架构进行分析,也有选择使用ETL将业务系统拉到自己的DB进行BI+DB进行分析的架构,本质上来讲这种架构都是我们常说的“大泥球”架构,由内嵌系统演进成大泥球架构相对是比较容易的。
即便是数仓,也是可以进行分层设计的,像在星形模型/雪花模型上建立Cube,基于Cube再提供MDX查询接口,来构建上层的分析呈现系统。这种结构虽然也是在一个端到端的看起来像是大泥球的架构,但是内部实际是进行了分层的架构设计,层次明确,基于不同的模型进行不同业务的抽象设计。
除了数仓之外,我们可以看到还有基于数据湖的数据架构,而在数据湖架构下,我们也有提供SQL接口,NOSQL接口的数据架构,SQL On Hadoop也是常见的数据湖架构。
Data Mesh是新型的架构设计,在Data Mesh下我们将数据域化,一种域化形式是闭环服务形式,也就是一个平台提供工具的同时还提供结果管理服务,并且只能在平台内部完成全生命周期的管理,即Data as a Service。另一种形态则是平台提供数据和工具能力,但是工具能力为可选项,业务可以使用自己的工具,也可以使用平台的工具,这个时候便是Data Platform as a Service。
增量变更
提到增量变更,可能大部分人会想到持续部署,小步提交这种敏捷软件研发的特征,从大的方向来讲我们如果做好了这些,那边整体模型便已经展现出了增量变更的特点。
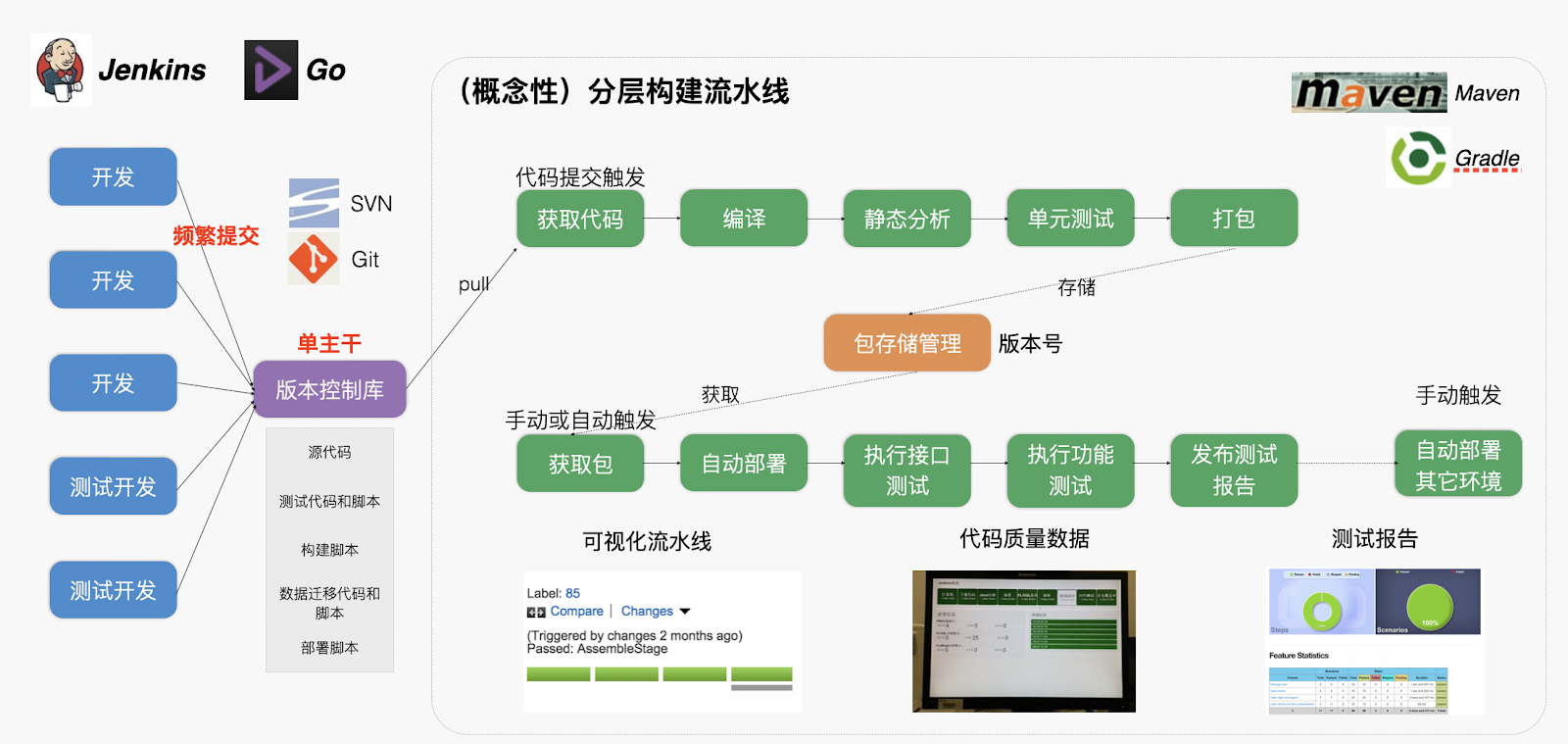
但是增量变更并不只是持续部署,小步提交这些操作。持续部署,小步提交,TDD测试覆盖等维度体现的是持续交付,侧重点在于迭代式的交付,核心还是交付,但是增量变更的点是在于变更,并且可以基于小步修改的变更。
增量变更对于数据领域的架构来说,相对于支撑业务流程的业务系统会稍有不同,虽然大体维度相差无几,但是各自关注的侧重点是不同,因此对于数据架构来说,从这个维度来看,变更可以分为:
开发级别变更:根据业务需求实现一个数据流水线,或者根据业务需要,开发一个数据服务,是否可以快速增加,是否给予了开发者足够的基础服务,尽可能少的减少非业务需求之外的开发。
部署级别变更:对于某一类业务,需要新增一个组件,或者新增一个数据构建空间,系统是否可以快速对此项快速进行上限部署发布,新实现的流水线是否可以在既定的时间内部署到线上。
架构级别变更:当业务发生切换或者演进的时候,架构是否足够结耦可以随着业务的需要,不断的进行调整用来快速相应业务的变化。
流程级别变更:除了业务本身的内容发生变更之外,有时会存在流程与审计所带来的额外的影响,于是系统不得不针对这种非功能性的合规进行快速的整顿以符合流程要求的上下文切换。
而所有变更所依赖的基准条件都是可测试,例如在开发层面有了测试,才可以通过测试来保障每次提交,构建出的代码在不破坏架构特征(规范)的前提下,对系统进行增量修改, 而在构建上采用持续交付/部署流水线又可以在系统执行变更时自动化测试的执行与校验。
引导性变更
引导性变更,本质也是变更,但是重点是在于引导,也就是说我们得现有对应的引导维度和度量方式,才有变更的基础,和增量变更所不同的是增量变更指的是可以很容易的在现有的系统架构上进行变更,而这个变更可能不一定具有引导性,例如我们用最小的成本快速变更修改了一个Bug,确实这个变更是增量变更,同时也具备业务价值,因为它实实在在的解决了问题,但是它可能不具备引导性。
那么我们如何去定义这个引导性呢?关于数据架构应该有哪些度量维度,这个我们放在后面的适应度函数这个环节去讲解,引导性就是在有了度量维度和引导方向后,进行对应方向的变更,引导性变更可以引导相关的变更更加适应业务和技术环境的变化。
适应度函数
适应度函数这个概念来自于遗传学,如果是站在软件开发这个领域来看的化,具体的呈现形式就是一个个的度量维度和验证方式,其实现力度有大有小,例如可以是小到单元,E2E测试,甚至是控制代码风格的checkstyle,也可以是大到度量架构的抽象维度,也就是说凡是可以验证架构特征的“功能”都可以称为适应度函数。
回到我们要解决的领域来看,数据这个领域的特点在于量变引起的质变导致整体端到端的解决方案需要被重新设计,这不得不谈大数据的5V特征:
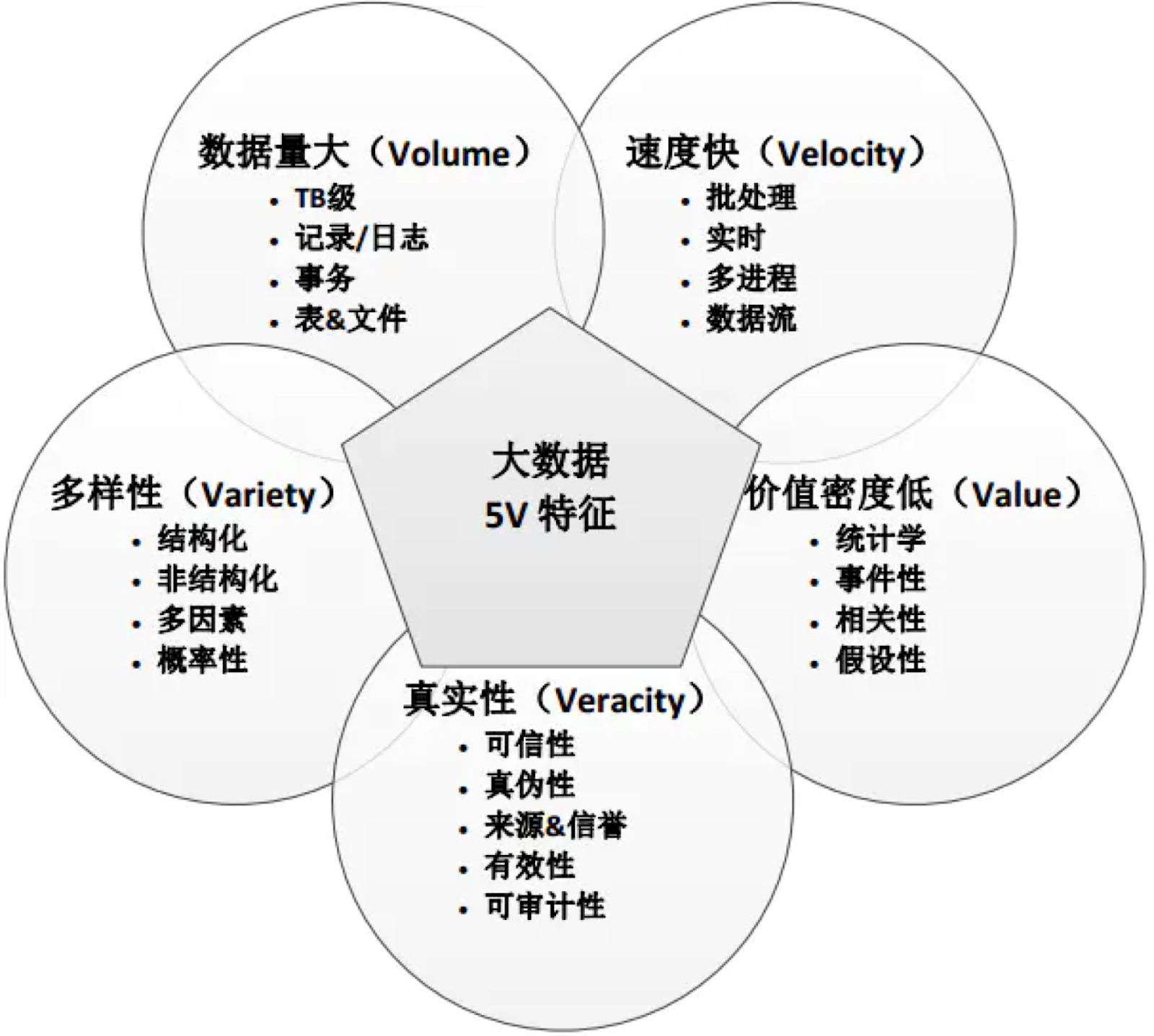
本次我们不具体展开5V特征以及其代表的方向,但是可以看出在数据领域从业务需求的产生到基础设施的建设都与一般的软件架构设计有着较大的差异。5V代表着我们对大数据业务诉求的定义,同时也代表着需要满足这样要求的系统,应该恪守的维度。

站在可引导和度量架构的视角来看,我们认为数据架构的适应度函数可以由如上图呈现的Data和Data Ops两个维度来构成,每个维度又有不同的权衡指标。
我们在定义适应度函数的时候,我们考虑函数有:
- 数据流水线平均恢复时间
- 变更失败比例
- 数据质量监控
- 部署失败比例
- 数据流水线部署频率
- 数据血缘
每一个维度下,我们需要详细设计具体的测试函数,其中部分可能能够以自动化测试的形式体现,然后固化在平台开发工程之内,部分或许无法自动化,需要使用类似监控报表这种手段进行监控。
架构解耦与演进
既然数据架构可以分为不同的类型,并且数据架构有着对应的适应度函数进行评估,那么我们探讨探讨数据架构如何进行演进。对于架构来说,既然叫演进,我们自然是希望用最小的变换,最低的成本,最短的时间达到我们预期的效果,要达到这一要求,似乎架构之间的模块做到足够好的结耦对于结果来说是很重要的。
好在大数据目前来说,还没有一个单一的组件就能够涵盖一切场景,通常是众多组件进行组合,然后利用组件现有的能力以服务化的形式进行集成,而不是像常规软件开发以库的形式进行集成。这样的生态环境天然的带来了结耦架构的便利条件,但是这还远远不够,这最多只算组件之间的结耦。
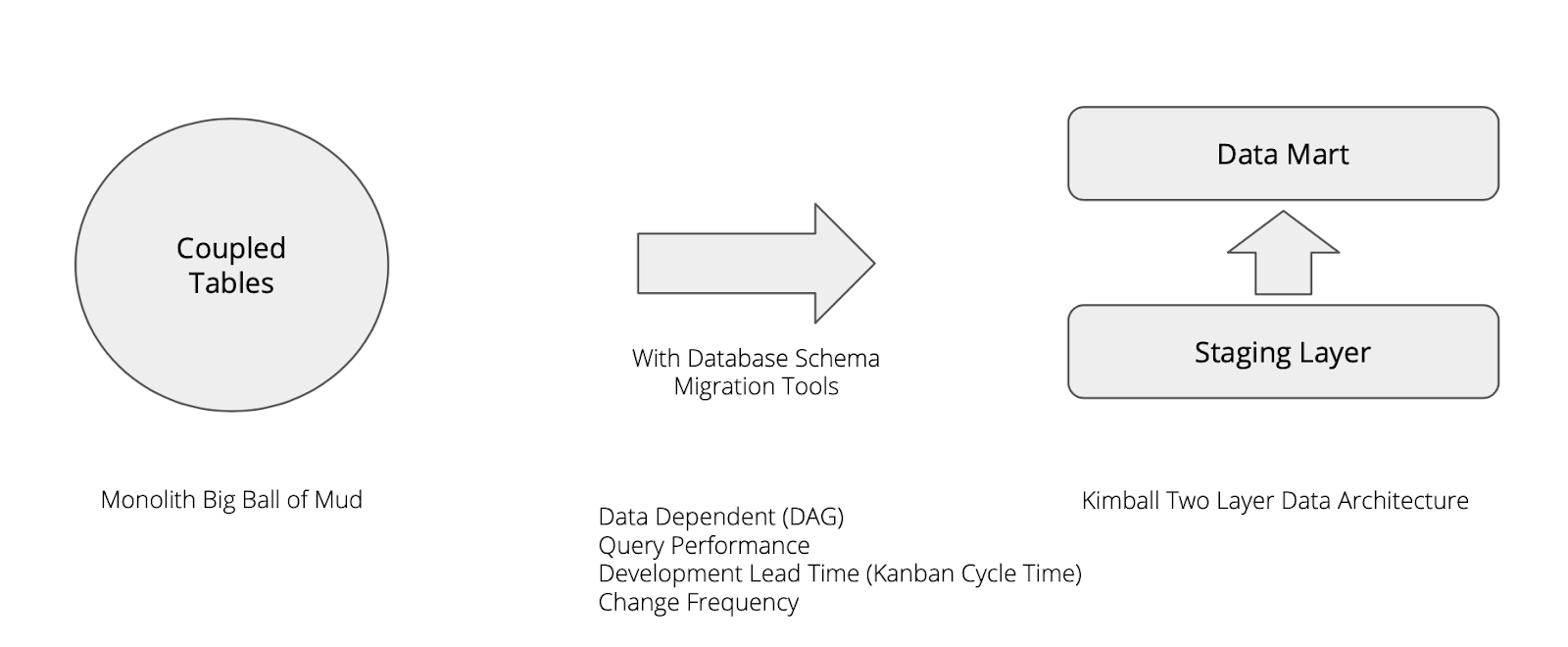
对于将数据分析所需要的数据耦合在业务系统之内,没有区分业务和数据分析这一类系统,我们是很容易的将其演进到两层数据架构,从改造来讲甚至不需要进行代码级别的修改,仅仅通过部署层面就能达到目的。例如直接创建主备的两类数据库,分别部署两套系统支撑不同场景,在后续重构的过程中,再逐步的阉割不需要的功能。
这种手法的思想和我们在做遗留系统改造的时候如出一辙,那么对于这种系统来说,我们可能用来使用的适应度函数会有:
- 数据依赖:数据是否存在交叉引用,是否存在业务和数据之间没有进行分离。
- 查询性能:每一次数据的处理请求,是否能够满足业务侧的需要。
- 开发周期:新增数据需求的时候,从任务产生到看板到done之间的时间周期。
- 修改频率:在固定的时间内可以支持多少次的变更调整。
这种系统架构之间的演进,通常是一个数据系统最原始的起步的形态,大部分在业务系统不是很复杂,同时数据需求不是很旺盛的时候,这种实现是最为直接和有效的。
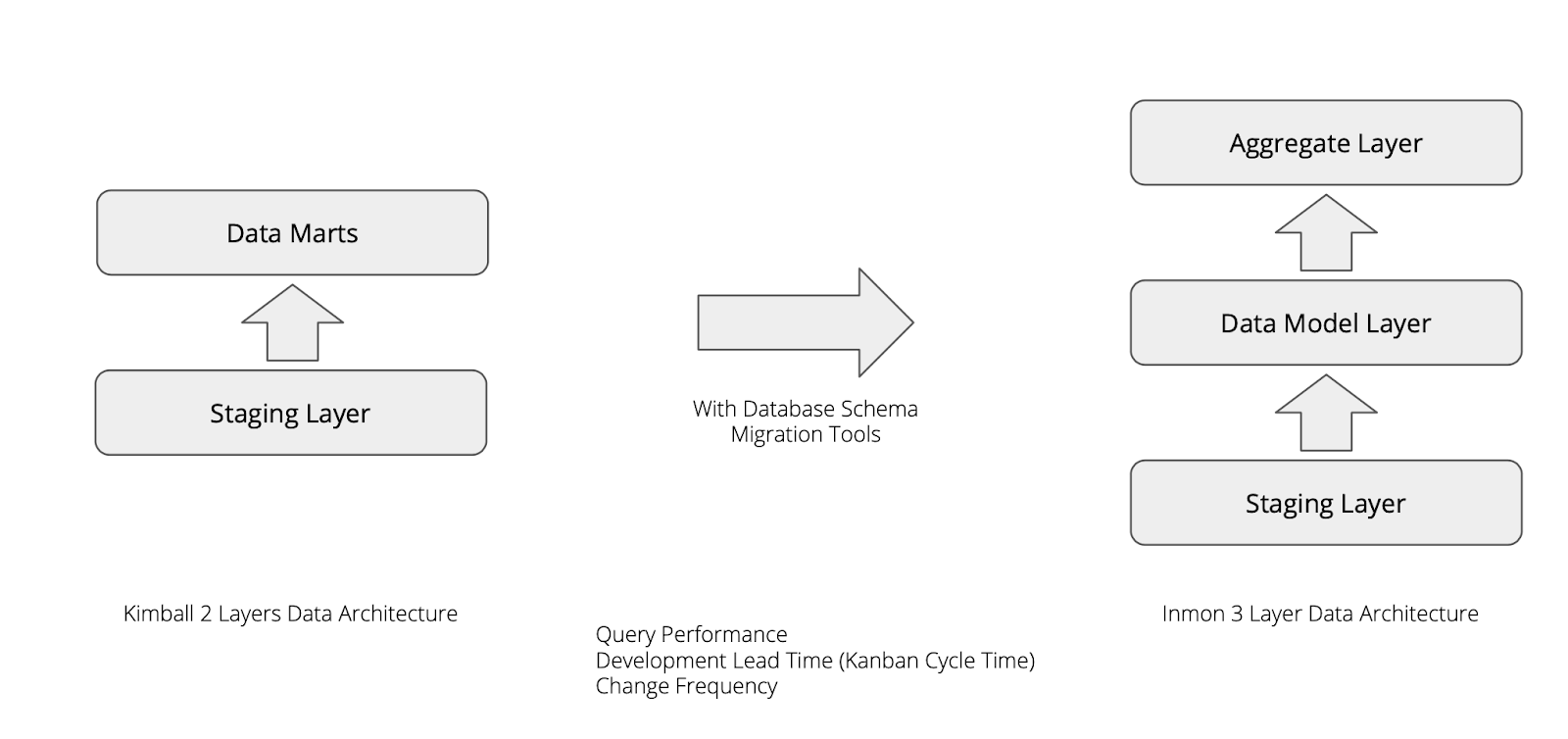
那么对于已经是两层架构的系统来说,这类系统通常是底层有一个大而全的数据库,此数据库里面存储了业务所需的所有表,但是表并没有经过仔细的设计,表逻辑和业务直接的支撑关系通常被固化在了上层分析的逻辑里面,可能是程序员开发的代码,例如Java,PHP等,也可能是SQL借助于某些BI工具直接实现的。
这种系统架构即便是今天在新构建系统的时候,依旧会有很多人会做这样的选择,例如直接使用Hive或者Presto作为底层的存储,然后上层提供JDBC的接口做数据分析。对于这类系统来说,也可以稍微做一些小小的改动,就可以让整个架构看起来相比之前,更加的美好了。
所以我们在两层架构中,新增一个对应的数据模型层,用来将原始数据和业务需要的数据进行结耦,虽然他们最终的实现可能依旧存储在一个组件,甚至可能就是存储在一个数据库中,但是从设计层面我们已经通过约定和协议将他们进行了分离,在未来仅仅是将他们换一个位置而已,这样的改变就会变得很容易。
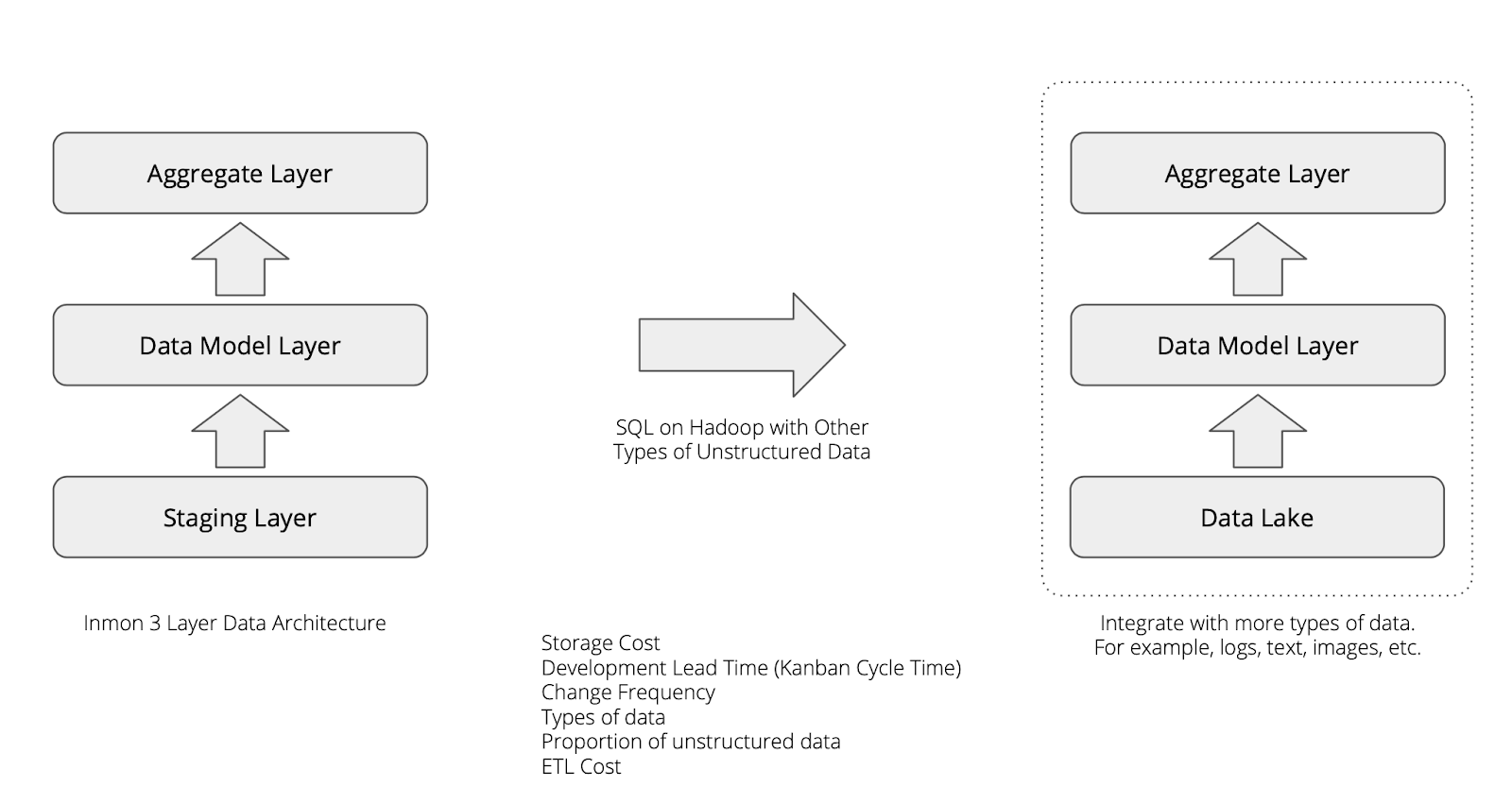
对于三层的数据架构来说,我们依旧可以做一些小的调整,例如在当下所支撑的业务场景不发生任何的变化之下,我们将底层的基础设施进行替换,这样的话我们即保留了原来的业务不受影响,同时也获得了更好的额外能力,那么牵引我们做这样的改变的适应度函数,除了前面提到的之外,还有新增加的:
- 存储成本:之前的存储都是基于事务型的存储介质,拥有较高的存储成本,我们可以使用成本更低的文件系统进行替换。
- 数据类型:除了常见的关系型的数据结构外,还能支持更多的类型,例如文本,图片。
- 非架构化数据的比例:之前的架构不是不能处理非结构化,而是成本相对较高,因此非结构化数据的比例不能太大,如今我们可以处理更大比例的非结构化数据。
- ETL的成本:更加快速的支持更多的ETL程序进行运行。
也就是说在良好的三层架构之下,我们仅仅是进行一个基础设施的调整,就能够获得非常好的效果,而这些效果来自于我们设计的适应度函数的牵引。
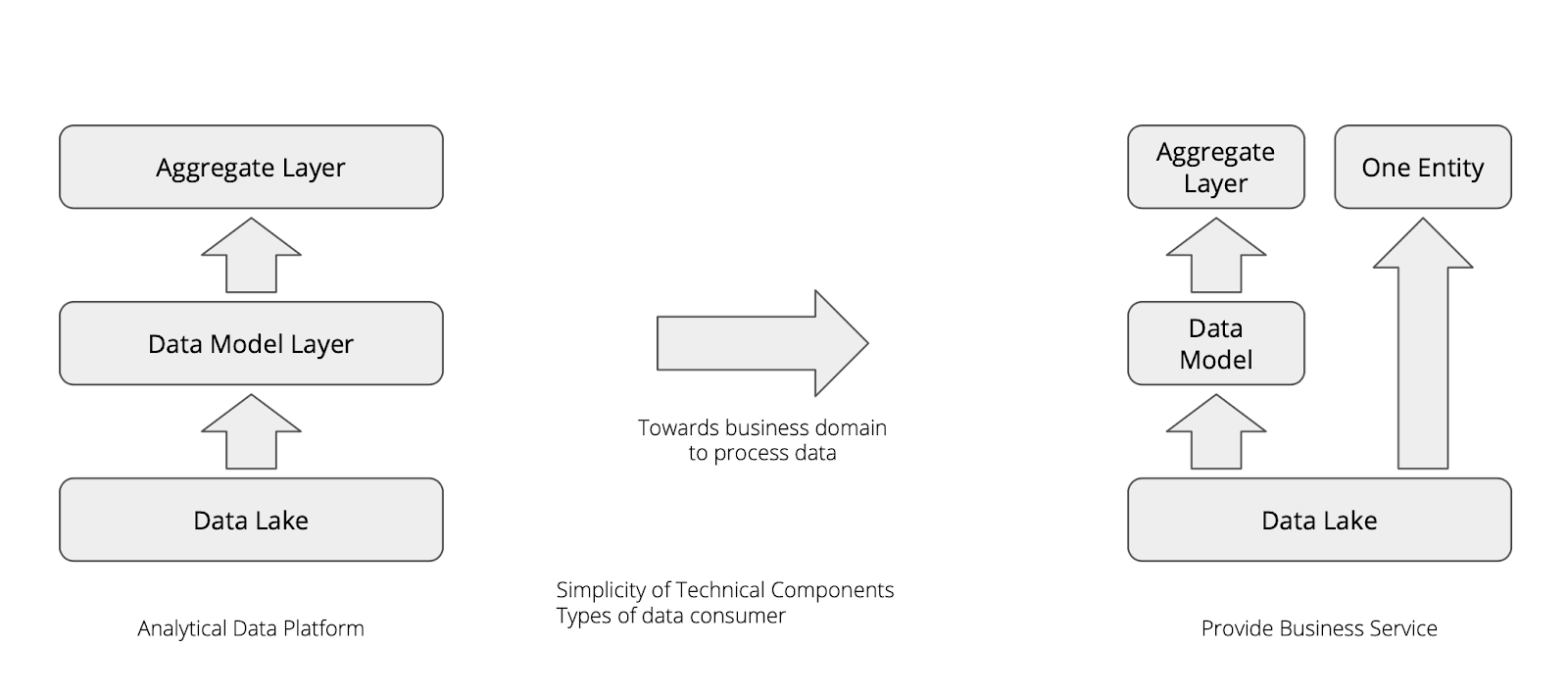
让我们继续往下看,三层架构所支撑的本质上还是一个分析型的数据平台,并没有提供直接的业务服务,那么如果在“提供简单的数据服务给业务侧进行消费”这样的适应度函数的牵引下,我们就需要思考对系统进行怎样的改造,可以满足这样的诉求。
于是我们发现在原始的数据存储架构知识,我们需要新实现一个数据服务,用来提供支撑业务运作需要的实体,这个实体是直接发送到业务侧,并不是提供给分析所需,甚至需要构建一套用来支撑数据发布的服务。
但是这样的改进并不会对原始的架构产生较大的影响,而是在原来的体系下很快的扩展了新的能力,并且复用了之前的架构已经存在的基本的数据底层的能力。
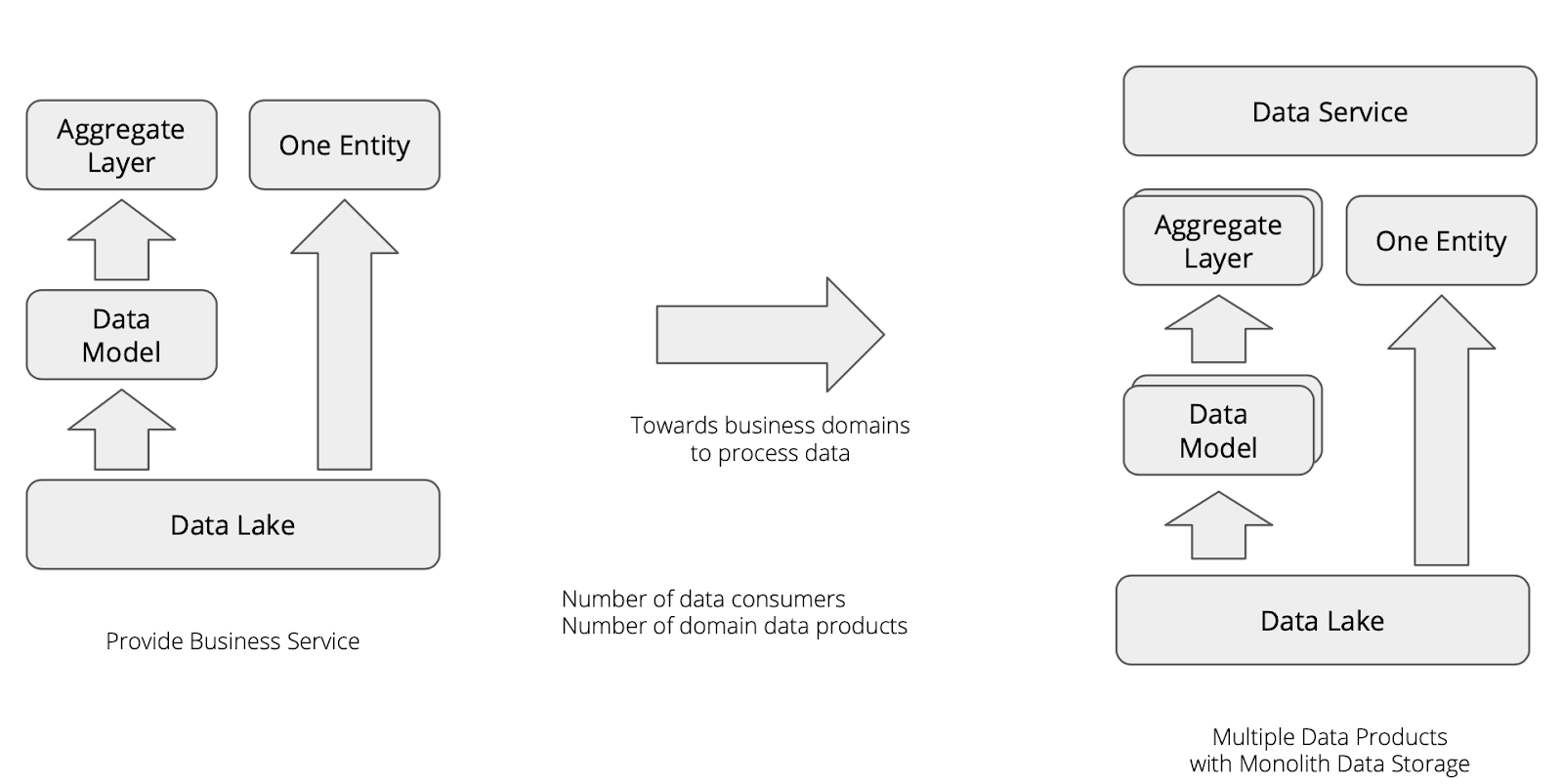
业务总会进行发展,既然存在业务侧的数据消费者,那么总会变成这样:
- 我们需要支撑更多的数据消费者。
- 我们需要支撑更多的领域数据产品。
也就是是这个时候,数据以产品,或者产品服务的形式提供给外部进行消费,在这个平台里面:Data As A Service,平台除了提供数据外还需要提供对应的数据分析能力,这样就成了一个类似于数据的SAAS平台,更好的称呼叫DAAS。
从架构来说,我们需要提供多类工具,也是之前的扩展,同时需要新构建支撑不同业务的统一数据入口门户,用来整合数据平台下的多种能力,这就是数据服务层的扩展,目前类似数据中台的思想,便是这样的一套解决方案。
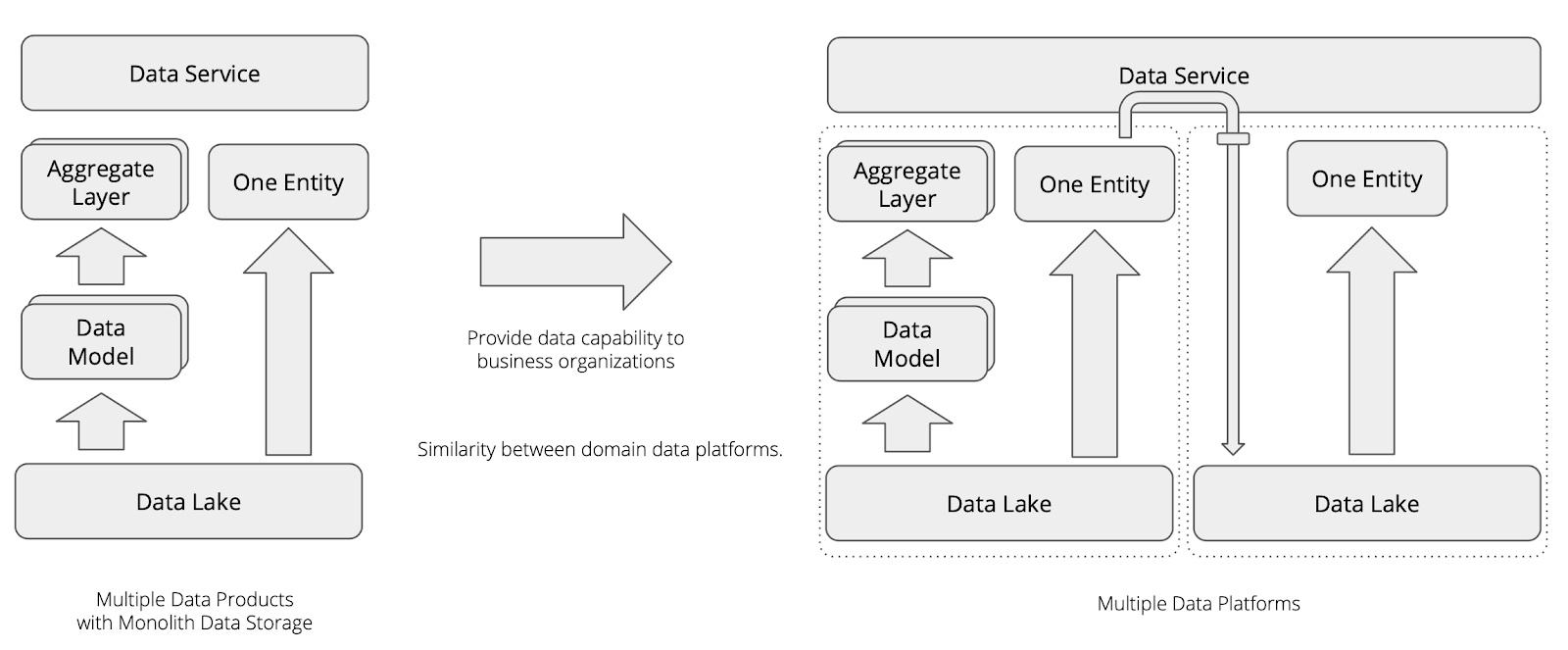
光有SAAS还不足以满足业务的需求,在快速相应和足够的灵活度的牵引下,我们总需要给予数据使用者足够大的想象空间,于是系统便会成为提供一个数据开发环境,或者提供一个数据工作空间的基础设施。
对于这样的演进来讲,牵引我们的不外乎是“多租户”,“多工具支撑”,“业务快速定制自己的数据服务”。因此我们需要将数据平台底层更基础的组件以服务的形式暴露出去,同时需要给每一个数据消费者初始化一个用来支撑对方进行数据消费的环境,于是前面的整个平台就成了一个租户的工作空间,我们需要不断copy多个类似这样的平台服务,也就是平台是PAAS。
而不同的租户直接的数据,有一个合理的流通机制可以进行共享和消费,每一个业务方有自己的工作空间和消费组件,目前大家提到的类似于Data Mesh的数据开发和协作形式就是这样的工作思想。
在这样的设计下,每一个业务线,或者一个业务域,可以独立拥有自己的工作空间和工具,也就是可以使用平台提供的工具,也可以自行使用自己的工具,和平台之间是非常结耦的结构,仅仅存在数据之间的交互和传输即可。
结尾
经过前面的总结和梳理可以发现,我们在做演进式架构的时候,并不是需要启动一项庞大的改造工程,对现有的系统进行大面积的重构或者重写。而是我们发现这个系统呈现出的一些特征,和我们整理出的对业务有价值的适应度函数,围绕这个度量维度,进行小步的修改,这个小步可能都不需要修改代码,仅仅是流程和部署的改变,但是我们总是在做调整和改变,每一天整体的架构都相比之前更好,这样这个系统就会逐步的处于一个可以快速演进的状态,记住演进式数据架构的中心点:外部引导变得更好,内部优化,不要更差。
扫码手机观看或分享: